一
缘起
敦煌文献发现于1900年,至今已有120余年。百年来,各国学者通过对敦煌遗书、敦煌莫高窟及相关文献、文物的深入研究,在世界上创建了一门新的学问——敦煌学。敦煌文献中蕴含了古代世界四大文化、六种宗教的信息,它的面世与研究,促成了敦煌学在20世纪成为世界的显学。
随着互联网、人工智能等数字技术的发展,敦煌文献数字化,即利用数字技术来保护、整理与研究敦煌文献,已经成为敦煌文献研究工作的重要方向。古籍数字化过程中,非常重要的一项工作是古籍文本的数字化,这是古籍真正融入数字社会的基础。
2021年8月,如是研究院与方广锠教授、释定源法师所在团队交流、探讨了汉文敦煌文献数字化方面的工作。研究院提出训练一款针对汉文敦煌文献的人工智能OCR引擎,以促进敦煌文献数字化工作。敦煌OCR引擎的研发工作得到了方老师团队的大力支持,也得到了如是研究院人工智能OCR技术合作方,即华南理工大学金连文老师团队的大力支持。
二
数据标注
为了训练这款敦煌OCR引擎,研究院与方老师团队合作挑选了5000张具有代表性的敦煌图片,包括4600张楷书,400张草书和行书(以草书为主),之后与金连文老师团队合作进行了敦煌数据标注工作。
敦煌文献大部分是手写体,还包括部分的草书和行书,版式也不规范。相比雕版古籍而言,它的标注工作要复杂很多。为了规范、有效地开展敦煌数据标注工作,研究院专门成立了敦煌数据标注项目组,由校对部副部长王金雷任项目经理,以研究院的人工智能OCR技术和如是古籍数字化生产平台为依托,从社会上招募了一批专职校对员进行标注。
数据标注主要包括切分标注和文字标注。切分标注从2021年12月16日启动,至2022年2月16日完成切分校对、审定,历时2个月,参与人数达23人。
文字标注要复杂很多。敦煌古籍中异体字的现象很普遍,“今”字常常写作“𫝆”,“若”字常常写作“𠰥”,虽然字形非常相似,但仍属于不同的计算机文字。我们采用通字校对的原则进行校对(即采用与图片字最接近的计算机文字进行校对,如:今与𫝆作为两个不同的字),就需要把它们区分开来。另外,400页的草书和行书,还需要找懂得书法的专门人才进行校对,因此文字标注也分成了楷书和行草书两个小组分开进行。楷书文字标注从2022年2月23启动,至6月20日完成文字校对、审定,历时近4个月,参与人数达28人。行草书文字标注从4月8日启动,至7月7日完成文字校对、审定,历时近3个月,共4人参与。
图1 敦煌数据标注的甘特图
参与数据标注的人员包括佛教僧人和居士、敦煌爱好者、在校学生、退休教师、在职人员等等。在他们的参与和帮助下,研究院得以顺利完成了敦煌数据的标注工作。
三
引擎训练及测试
OCR文字识别技术有字符级(简称字引擎)和文本行级(简称行引擎,在古籍中又叫列引擎)两种类型,OCR的文字识别过程又可分为切分和识别两个步骤,加上训练数据可分为楷书、草书两类,因此,总的引擎分类如下表:
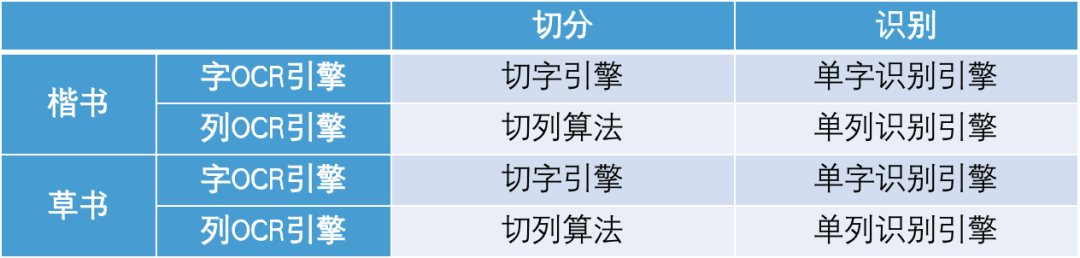
表1 敦煌OCR引擎分类
单独的字引擎或列引擎都可以实现文字识别的目的。为了更好地辅助人工校对,如是研究院的OCR技术采用的是双引擎模式,针对同一个文字,会利用字引擎、列引擎分别处理给出识别结果,计算机结果以字引擎为准,列引擎结果供参考。
(一)切字引擎
敦煌切字引擎是在已有的古籍通用标注数据基础之上,加入敦煌切分标注数据进行调整训练而得到的,切字引擎没有对楷书和草书进行区分。2022年2月27日,研究院将敦煌切分标注数据交付给金连文老师团队,开始进行切字引擎的训练。3月1日,金老师团队反馈第一次训练结果。随后我们对引擎进行了测评,针对发现的问题(包括漏切、多切或者切分得不太理想等)进行讨论,然后重新训练。期间,由于标注数据、引擎训练等种种问题而进行重新训练,前后迭代了5次,至5月15日,敦煌切字引擎达到预期水平。详情可参看《敦煌OCR引擎工作进展》。


图2 敦煌楷书切分效果


图3 敦煌草书切分效果
(二)切列算法
图片的切列采用的是研究院自主研发的切列算法。算法基于切字的结果进行计算,不仅可以计算出版面上列框的坐标,还可以计算出列框内字框的顺序,尤其是针对夹注小字的情况进行优化,可以较好地解决夹注小字顺序的问题。
(三)楷书单字识别引擎
敦煌楷书单字识别引擎是在研究院和金老师团队已有的古籍标注数据基础上,加入了4600页敦煌楷书标注数据(2310422个字,8074个字种,训练时每个字种选取不超过400个字图)后训练得到,一共可识别19048个字种。
引擎训练完成后,我们针对标注数据中的8068个字种,每个字种尽量选取了100个字图(不足100个,则按实际数量选取)进行测试,测试结果按通字校对原则(如:今与𫝆作为不同的字),准确率为91.96%,按正字校对原则(如:今与𫝆作为相同的字),准确率为96.42%。


图4 敦煌楷书OCR字引擎识别效果
(四)草书单字识别引擎
敦煌手写体草书的字体风格与雕版藏经字体风格相差太大,无法利用已有的标注数据,只有单独利用这批标注的400页草书数据(261682字,3546个字种,训练时每个字种选取不超过400个字图)进行训练。
引擎训练完成后,我们针对标注数据中的3546个字种,每个字种尽量选取了100个字图(不足100个,则按实际数量选取)进行测试,通字、正字准确率均达到99%以上。
敦煌草书标注数据的总字数和字种数都还比较少。一方面是由于未能全面梳理、掌握敦煌文献中的草书文献,另一方面是因为此次标注主要是针对敦煌文献中比例最大的楷书部分。期待未来能把这个工作做得更好。


图5 敦煌草书OCR字引擎识别效果
四
引擎已发布,欢迎使用
目前,我们已将上述引擎集成、发布在如是古籍数字化工具平台上,欢迎大家访问试用!(注册用户后,请联系管理员开通敦煌引擎的使用权限,方可使用。)
针对敦煌的列引擎还在训练中。此次发布的OCR引擎中,列引擎采用的是已有的雕版藏经列引擎。由于对敦煌OCR引擎的期待已久,加上双引擎是以字引擎为主、列引擎是辅,因此先将上述的这些引擎发布出来供有需要的人士使用,日后再单独升级列引擎。
工具平台网址是:https://guji.rushi-ai.net,海外用户如无法访问,则可以访问镜像网站:https://guji.world.rushi-ai.net。
图6 如是工具平台OCR界面
关于工具平台使用方法,详见《技术发布 | 如是古籍数字化工具平台用户手册》《工具平台使用Q&A》。
END
文字编辑 | 释贤度、黄家亮
审核 | 院委会
排版 | 王昕嫱




评论前必须登录!
立即登录 注册