手动搜索和提炼信息时,我们常常遇到这些恼人的问题:
• 信息太多,而人的阅读速度是有上限的;
• 信息太杂,要对查找到的信息进行多次筛选和过滤;
• 信息太晦涩,看不懂,而你需要一个通俗的新手村友好版本;
• 信息涉及多个议题,要从线性的文章中梳理出树状的结构、网状的思维;
获取信息的质量和速度,决定了我们决策的质量。如果能够「秒读」千百篇文献、指南、政策、规定、招股书、访谈纪要,快速得到大纲或精华内容就好了。最近 ChatDOC、ChatPDF、Humata 等 AI 文档阅读助手就赋予了我们这种能力:直接和单个或多个文档对话,在一问一答之间,化信息为洞察。
但是问题又来了,为什么有时候这类 AI 助手的回答表现很惊艳,有时候又差强人意?这跟 AI 工具本身的性能、技术原理有关,也跟我们的提问方式有关。本期文章将为你介绍:
1. AI 阅读工具测评;
2. 它们擅长的以及不擅长的;
3. 如何写出好的提示语(prompt)。
📱
AI 阅读工具测评
我尝试了 4 款 AI 阅读工具,先说结论:ChatDOC 从准确度和产品功能上显著优于其他几款,如果是严肃的工作/研究场合使用,ChatDOC 是首选。
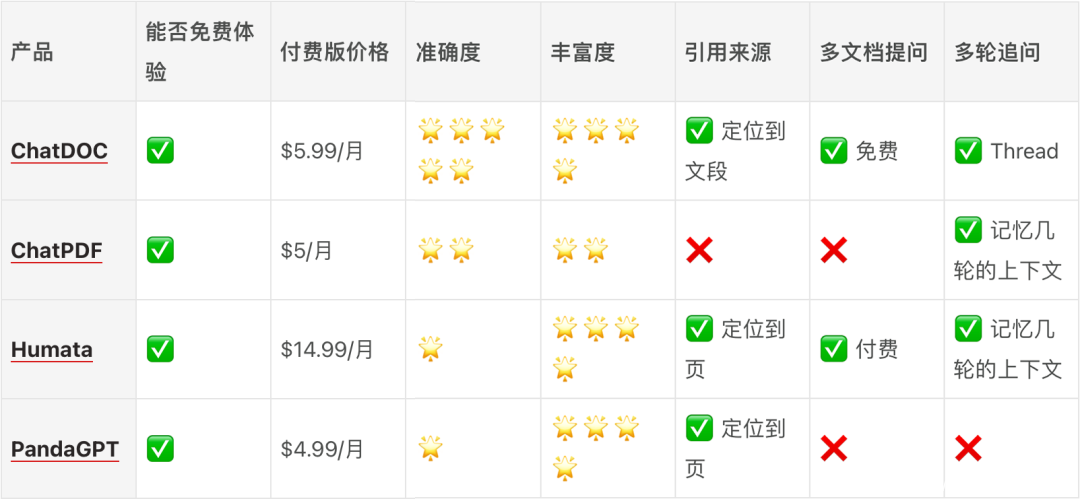
▍准确度
准确度是首要指标。如果提取的信息有问题,反而会给信息处理工作带来更多麻烦。从数据的准确度上看,只有 ChatDOC 具有可用性。
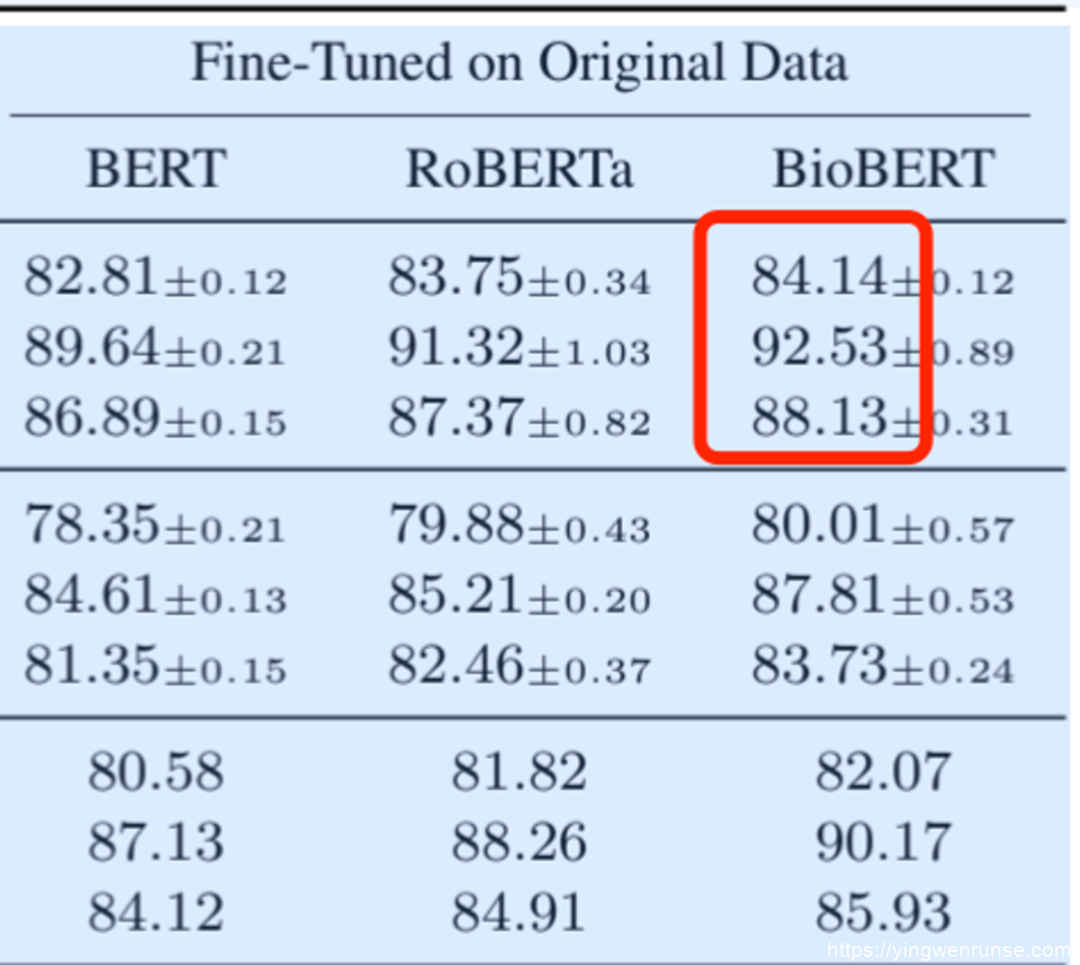
为了测试准确度,我分别在四个软件上传了同一份学术论文,对其中的实验数据进行提问。
What is the performance of BioBERT Fine-tuned on original data in dataset GAD?
原 PDF 中的实验数据为 84.14、92.53 和 88.13。对应的参考示例如下:
ChatDOC 全部回答正确,并精准定位到了原文表格:
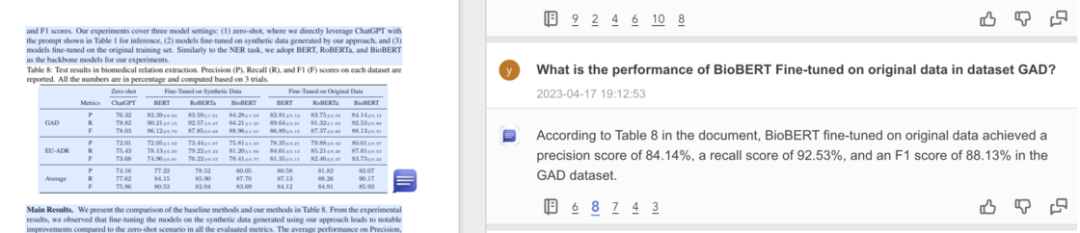
PandaGPT 找对了位置,但只给出了一个数据,数据还是错的:
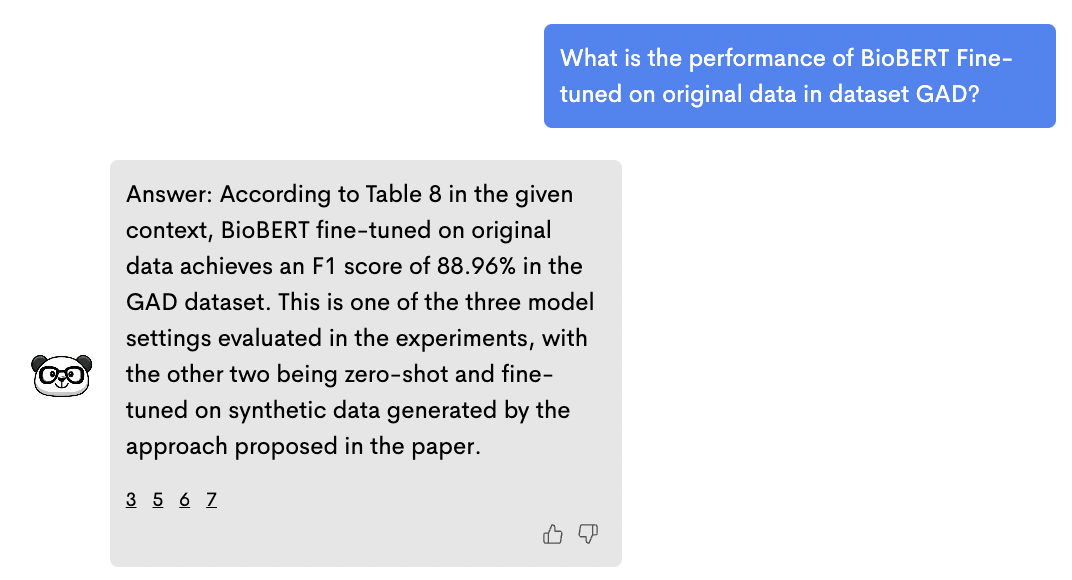
ChatPDF 不支持原文溯源,虽然找到了三个数,但给到的三个数据全部是错的:

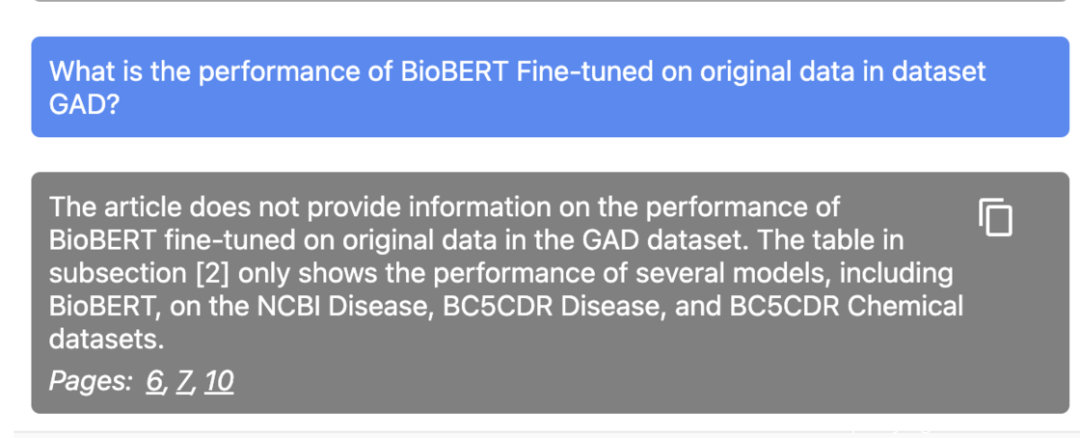
Humata 干脆摆烂了,告诉我原文中没有这个数。
▍丰富度
另一个比较刚需的场景是提炼、概括重点内容,因此对于上述文档,我又测试了一个摘要性问题:
总结一下这篇文章的主要内容。
结论是 ChatDOC、PandaGPT、Humata 的表现都不错,但 ChatPDF 给出的回答过于概括了。对应的参考示例如下:
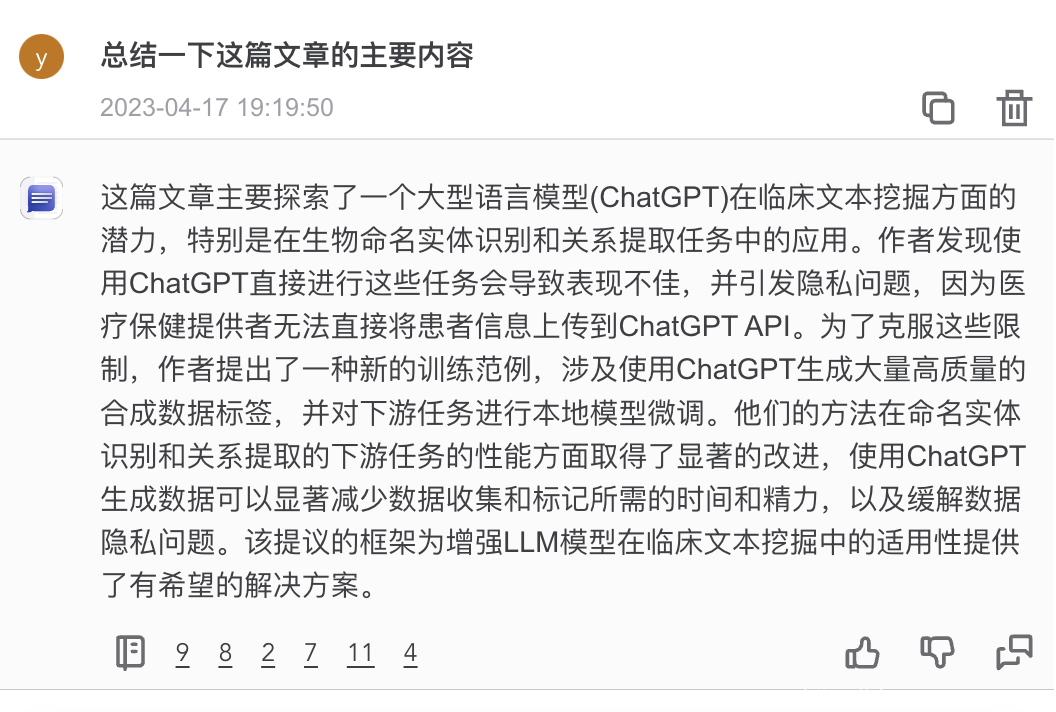
ChatDOC:表现不错,给出了有信息量的摘要。
ChatPDF:过于简略,对于了解文章的帮助不大。

Humata:表现不错,给出了有信息量的摘要。

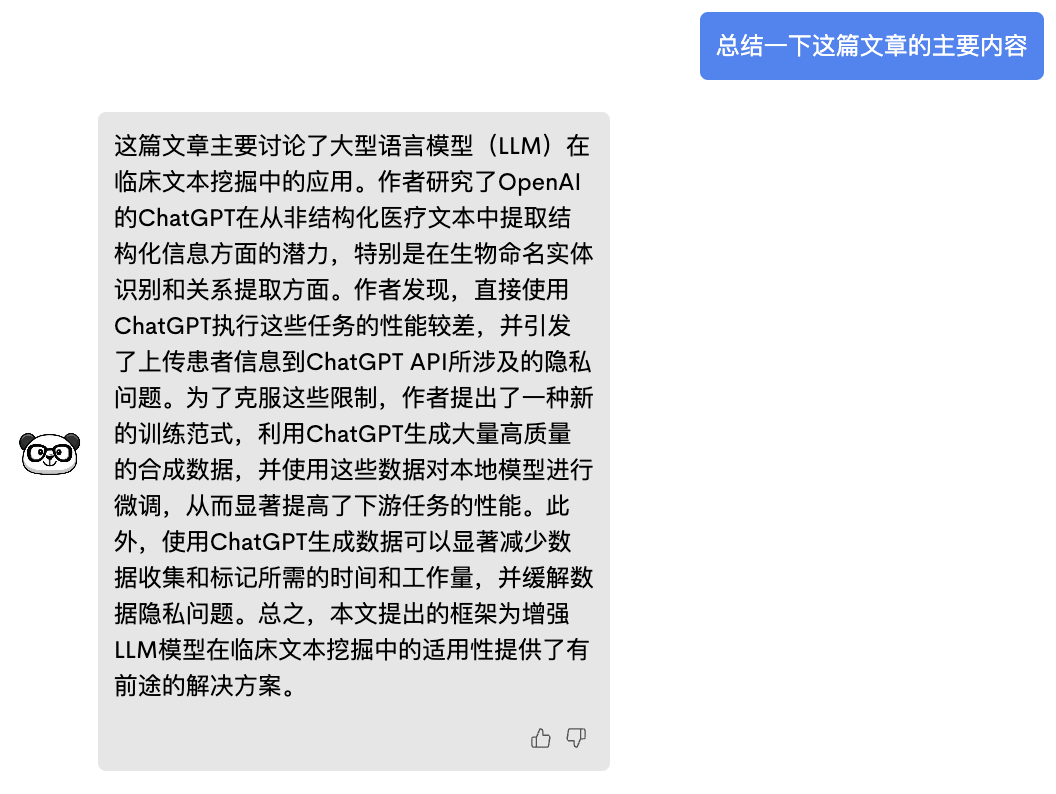
PandaGPT:表现不错,给出了有信息量的摘要。
▍引用来源
许多 AI 问答类的产品,包括 New Bing,为了规避大语言模型可能的胡说八道,都做了列出引用来源的设计。
ChatDOC 的引用做得很精细,回答中每一句话的末尾都给出了来源,且能一一对应;Humata、PandaGPT 的回答整体给出了引用页码,但颗粒度比较粗;而 ChatPDF 暂时没有这样的设计。对应的参考示例如下:
ChatDOC:每一个回答的每一句话都会给出来源,且精确到段落。
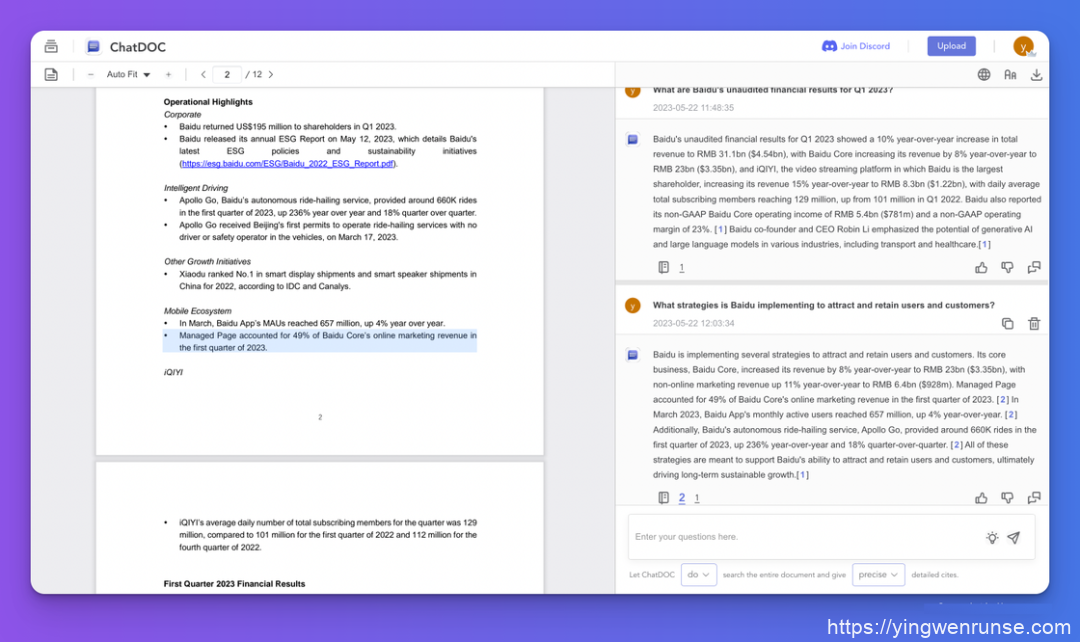
Humata、PandaGPT:对于包含数据的问答会给出来源,且精确到页;摘要、类比性质的问答,则不会给出来源。
ChatPDF:无。
▍多文档提问
ChatDOC、Humata 支持上传一个文件夹,对文件夹进行整体提问;ChatDOC 目前免费用户即可使用,而 Humata 是付费功能;ChatPDF、PandaGPT 暂不支持。
对应的参考示例如下:
ChatDOC 在操作上需在本地将文件收集到一个文件夹里,再整体上传。而体验上,ChatDOC 的多文档概要比较准确;在引用来源的处理上,给出了具体文档名称和页码。
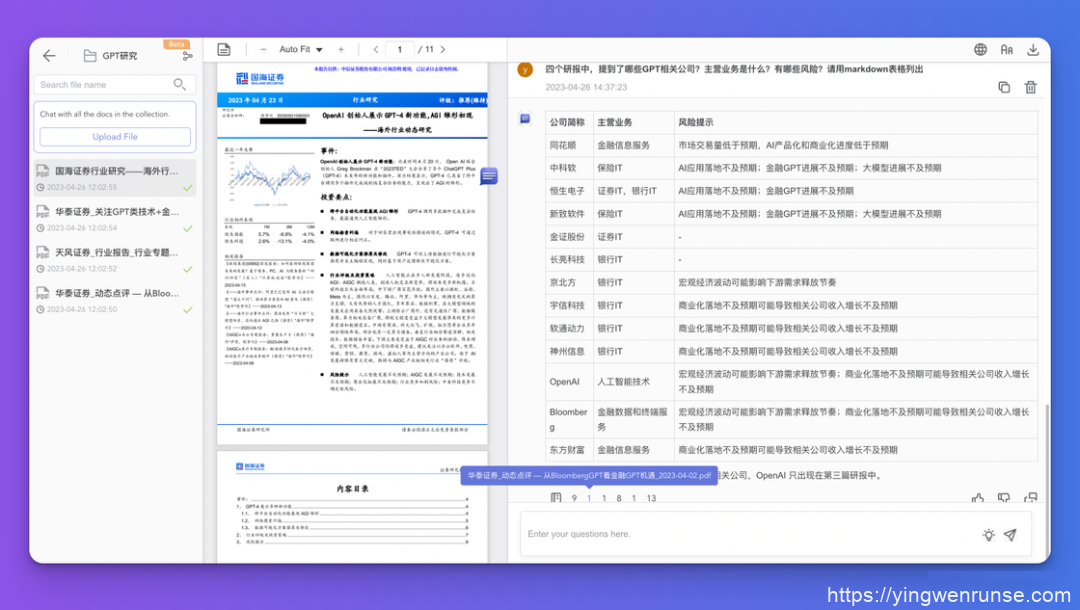
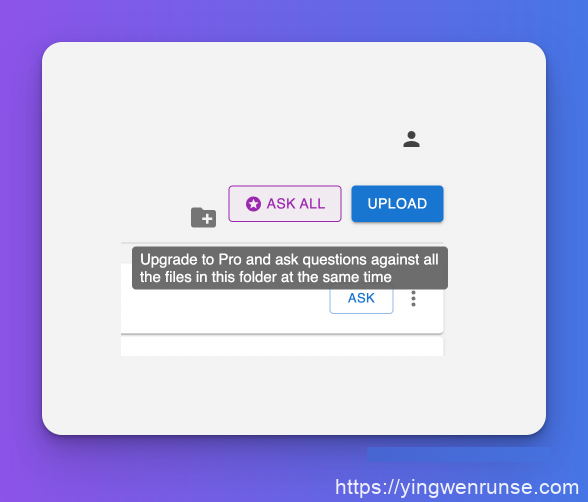
在操作上,Humata 免费版用户只能一个一个文件上传,付费用户支持多选文件上传。因为此功能仅付费会员可使用,所以我没有继续尝试。
▍多轮追问
关于上下文记忆以及多轮追问,这几款产品提供了两种处理方式,分别是开启 Thread 进行追问或者直接在对话框里追问,默认记录上下文语境。
在 ChatDOC 中,你可以选择保留/不保留上下文。ChatDOC 采用了类似于 Twitter上的「Thread」的概念:你可以针对某一条回答点击多轮会话按钮,开启 Thread,这样的对话记录了关于这个问题的上下文。
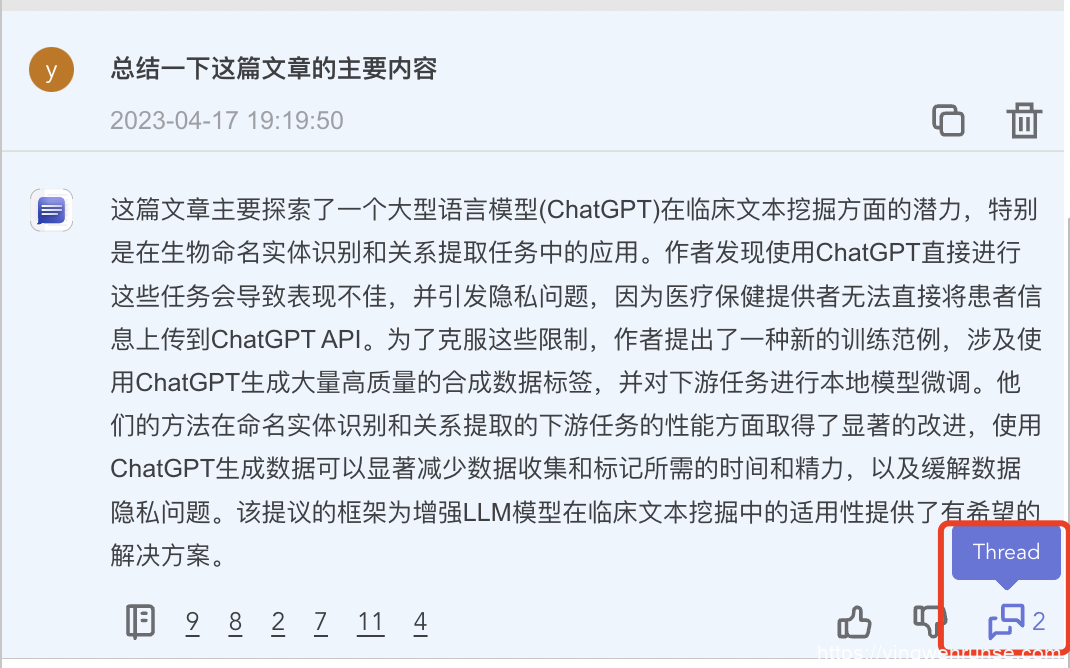
在多轮追问中,你还可以设定 AI 的自主度,是更自由的 Go Freely,还是严格按照文档回答。
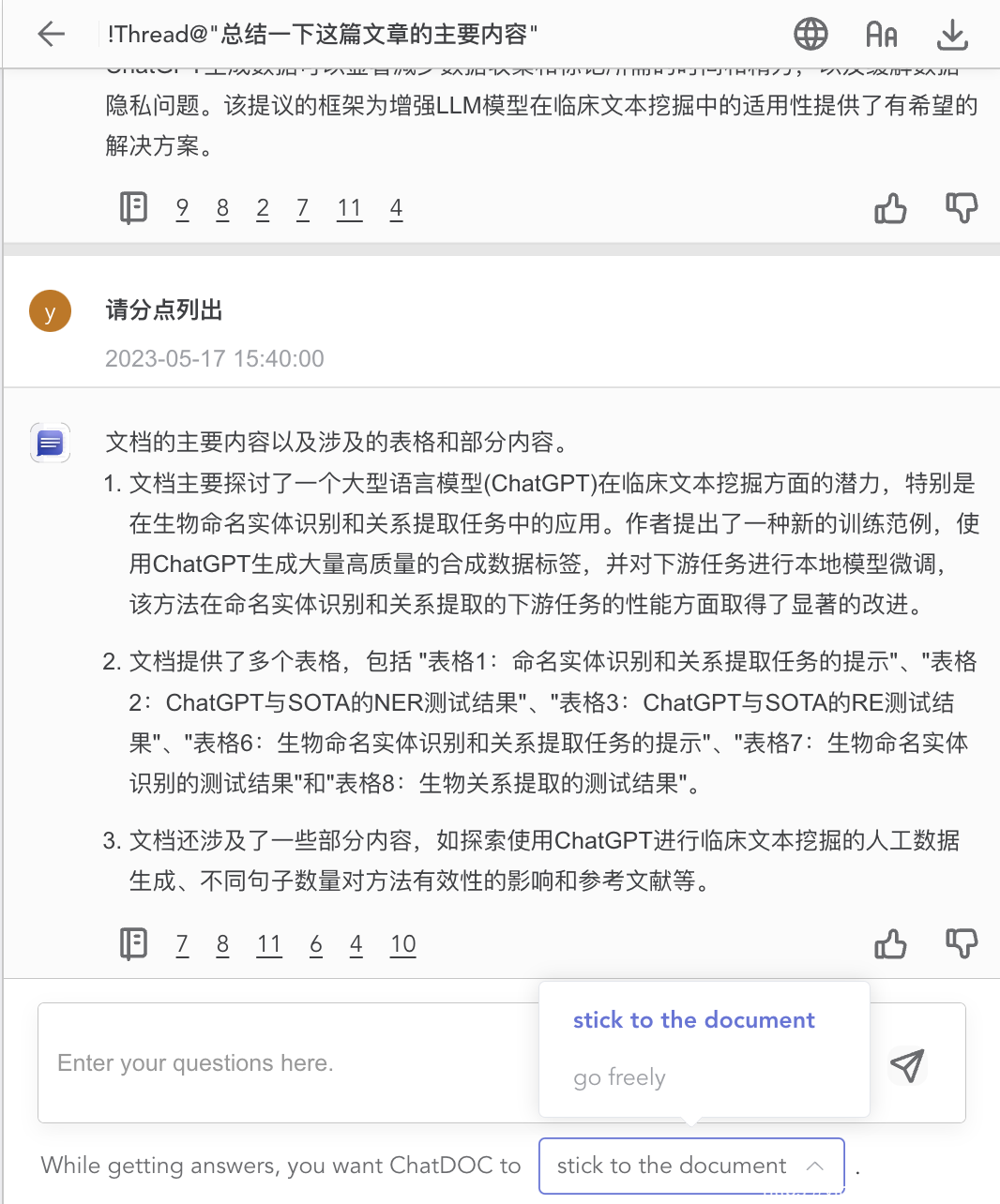
在单轮问题的主聊天框里,默认是不记录上下文的,每个请求都是单独的问答对。
其他三款产品没有 Thread 的设计,但 ChatPDF、Humata 明显是做了上下文记忆的,可以直接继续追问;而 PandaGPT 似乎没有记忆上下文的能力,无法追问。
对应的参考示例如下:
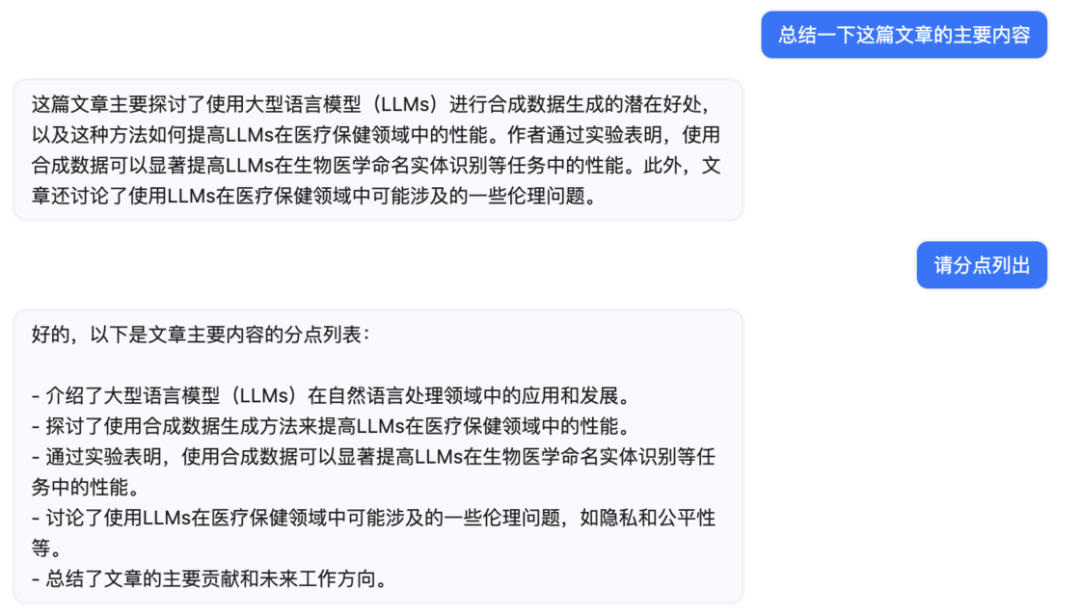
ChatPDF
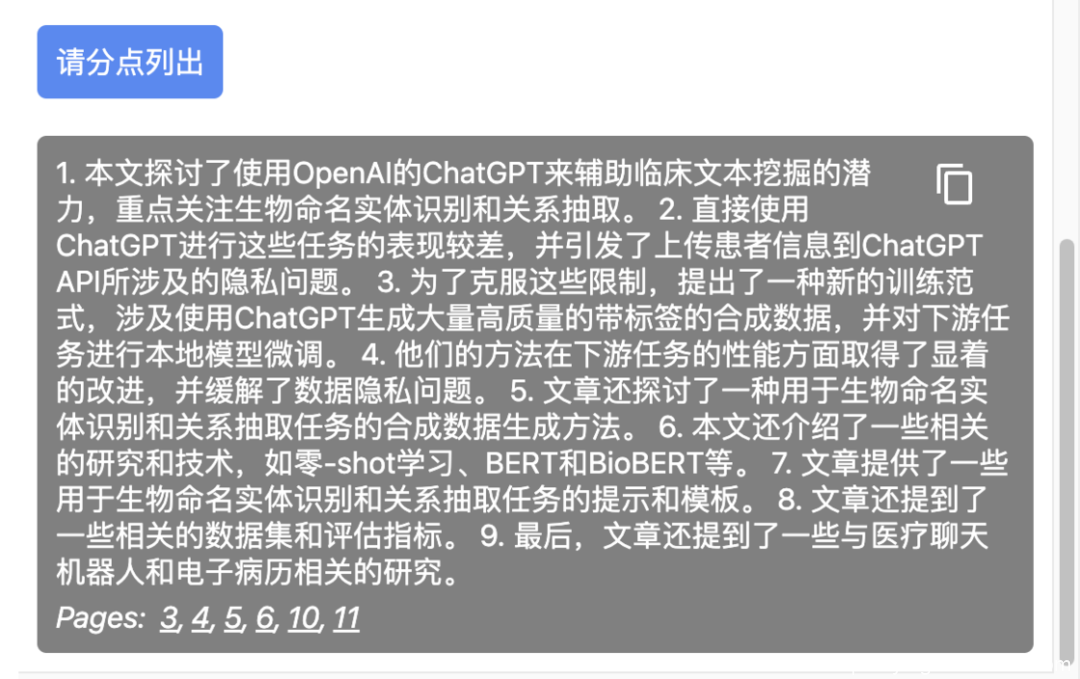
Humata
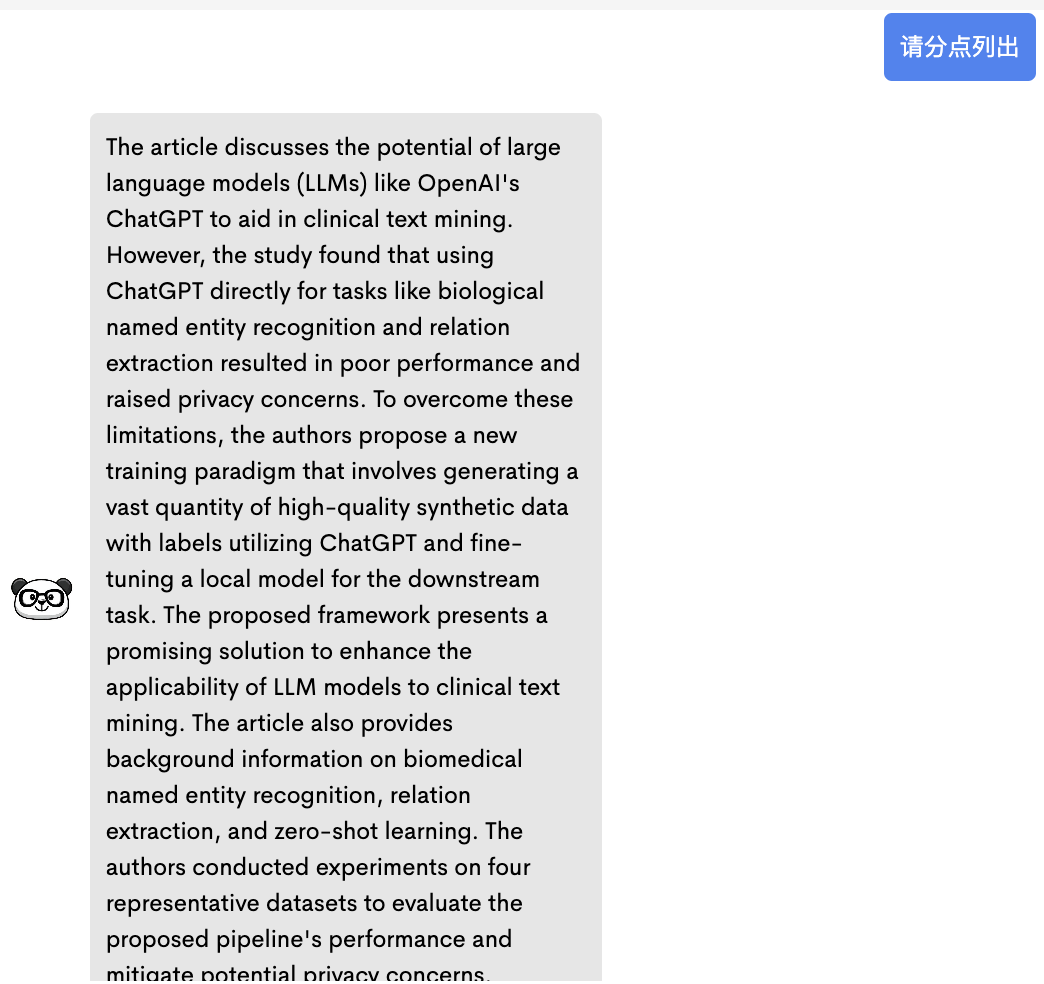
PandaGPT
这里就是仁者见仁智者见智了。ChatDOC、ChatPDF、Humata 都可以进行追问。ChatDOC 是针对某一问答进行追问,在 Thread 里保留关于此议题的所有语境;而 ChatPDF、Humata 则是自动保持几个问答之间的上下文,操作起来更直观,但问题在于轮次多了之后会遗漏早先的语境。
🤖️
了解 AI 工具
为什么几款工具会存在这样的差异?首先我们要理解「输入」和「输出」的概念。
所谓的「与文档对话」,在每一次对 ChatDOC 们的提问时,实际上是将我们的问题和文档内容作为「输入」,传给了大语言模型的接口,由它返回给我们「输出」,也就是我们在聊天中得到的解答。
目前由于大语言模型的 token 记忆限制(e.g. ChatGPT 的限制为 4096 个 token,约 3000 词;其他大语言模型目前的 token 限制一般在 2000-8000 之间),当我们提问时,ChatDOC 们无法将整篇文章的内容和我们的提问都输入进去,而是根据问题的语义,匹配相关度高的文章片段,传送给大语言模型的 API,得到最终答案。
也就是说,基于我们的提问,ChatDOC 们并非在整篇文章里进行检索,而是在最相关的片段里寻找答案。由此我们便可以总结一下 ChatDOC 的优缺点,做到趋利避害了。
▍ChatDOC 们擅长的任务
ChatDOC 们擅长处理基于「重点内容」的相关任务,包括但不限于:
1. 生成摘要,提炼重点。根据近似度匹配,它们擅长理解你的需求,并据此提炼重点。比如:
介绍本论文的主要内容;
总结说话人 A 的主要观点;
介绍该公司的投资策略及业务侧重点有何转变;
进行周度/阅读的数据整理。
2. 阐释概念,解释步骤。大语言模型接受过世界知识的训练,能够提供良好的背景信息补充和专业解释。比如:
「灾难性遗忘」是什么意思?
什么是大语言模型?
开一家淘宝店铺需要哪几个步骤?(你还可以通过多轮追问,让它阐释子步骤,从而在同一个主题下生成、组织和优化内容。)
3. 选中内容,智能分析。给到大语言模型的输入会完全囊括选中内容,因此 AI 能充分理解问题的上下文。比如:
选中个股数据,并输入「请对该只股票近期的数据表现进行点评」。
选中实验数据结果,并输入「请总结该实验结果的数据结论」。
4. 用结构化的形式呈现信息。让它帮你整理关于某一话题的信息,以表格或者大纲的形式列出。这个步骤实际上是在进行语义匹配的搜索,将碎片化的信息围绕几个关键词凝结起来,并以结构化的形式呈现。
分析一下基金投资策略的优缺点,打上标签,并以 markdown 表格的形式输出。
请依次告诉我这篇招股书的行业背景、核心技术、市场地位、公司历史沿革、主要财务指标、股东情况,用大纲列表的形式输出。
▍暂不擅长
而由于前文所述的记忆限制, ChatDOC 们暂不擅长精确的「全文定位」任务。比如寻找某个数据在原文中的精确位置(⌘Command-F 更能帮你达到这一目的),或者选中某条法规,让它列出这条法规在哪些文中的页数出现过。
Prompt 写作指南
▍指示要明确
请使用小红书流行的文案风格概括总结这篇文章。小红书的风格,特点是: 1. 引人入胜的标题;
2. 每个段落中包含表情符号;
3. 在末尾添加相关标签;请确保原文的意思保持不变。
▍把任务分解
选中的表格数据,是 A 公司近期的股票数据。请你根据选中的数据完成以下两个任务: 1. 请对 A 公司近期的股票数据进行点评 。
2. 根据收盘价计算每日收益率,并以表格的形式输出。
▍定义角色
你现在是一名帮助我回答税收相关问题的助理。回答问题时,请遵循以下要求: 1. 只回答跟税收相关的问题。
2. 如果你不确定问题的答案,请回答「我不确定」。
▍明确输出的格式
请使用大纲列表 outliner 的形式,依次告诉我这篇文章的引言、文献回顾、理论框架、创新点、研究方法、研究过程、主要观点和结论、进一步研究方向。 生成的回答格式如下,以此类推。每个部分的回答,要细分为多个子内容。- 引言 – 此处为引言内容。- 子内容 – 子内容 – 文献回顾 – 此处为文献回顾内容 – 子内容 – 子内容。
你是一名助手,旨在分析语音数据中的情绪。选中的内容是用户 A 的语音数据。评分范围为 1-10(10 为最高),请给出评分,并解释为什么给出这个评级。
▍把指令放到提示语开始
▍最后重复一遍指令









评论前必须登录!
立即登录 注册