人工智能,技能和生产率——来自出租车司机的案例
文章: Kanazawa K, Kawaguchi D, Shigeoka H, et al. AI, Skill, and Productivity: The Case of Taxi Drivers[R]. National Bureau of Economic Research, 2022.
引入
过去的文献表明,技能加强型的技术进步除了会提升生产率之外,还意外地强化了不平等现象。这种不平等现象主要在劳动力市场产生,因为这些技术不成比例地增加了高技能者的劳动生产率,从而使高技能者的收入增长远远快过低技能者的收入增长。但是AI技术和以前的技术有所不同,与其说这一技术是技能增强型,不如说是技能补充型。毕竟使用AI的门槛并不很高,它不是在你已经掌握某种技能的前提下增进你工作的效率,而是在你知道一件事能做出来的情况下帮助你高效完成。任何人,无论是低技能,中等技能还是高技能的劳动力,都可以使用AI辅助他们完成工作。
由此,AI与不平等之间的关系无法套用过去研究的结论。为了研究这一问题,作者仍从劳动力市场结果出发,研究AI技术的引入对异质劳动者的生产率冲击。为了更好完成识别和度量,作者采用出租车行业作为研究背景。第一,将研究背景定在单一行业有助于减少不可观测变量所带来的影响,也方便获得可比、可得的生产率指标;第二,出租车司机是体力劳动者,他们的生产率较好度量。作者使用了出租车司机为招揽客人所费的等待时间。在异质性劳动者方面,由于作者缺乏个人层面的数据,他使用生存分析模型里个体固定效应的系数作为生产率的衡量。我们常常谈论高技能和低技能者之间的收入差距,但这里的技能水平通常是指教育经历,比如计算机行业和体力劳动行业从业者的区别通常是在教育水平上。但由于作者把眼光限制在单一的体力劳动行业,只能使用经验和技巧作为技能水平的区分。可以说是这斟酌取舍的结果,也可以说是一种遗憾。
数据
作者的数据来自日本AI服务提供商AI-navi, 这一软件旨在利用人工只能技术为出租车司机提供基于地理信息的需求预测服务,帮助司机预测未来一段时间内在哪个位置更容易接到顾客。在产品的推广阶段,AI-navi积累了大量司机活动轨迹数据。一些作者关注的变量,包括获客时间等数据。
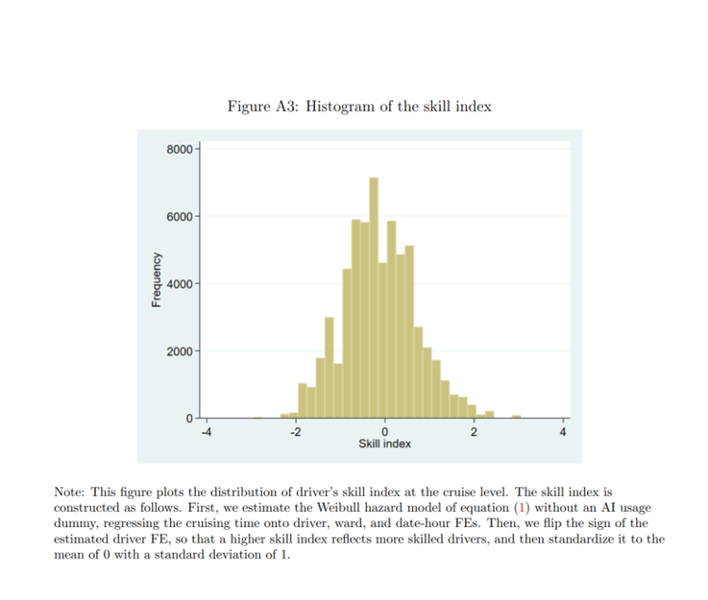
在产品的推广阶段,该公司把这一软件免费提供给Yokohama市的500名出租车司机,这一数字大概占该市全体司机的6%。对于这些司机而言,使用与不使用不是随机的,这也给评估AI的效应造成了困难。如下图所示,可以明显地看到,如果使用AI的决策是随机的,我们应该看到下图的两个分布大致一致。但是结果拒绝了这一想法。甚至在使用AI的情况下,用户的获客时间平均更长。可能的原因是选择偏误,只有当出现了获客的困难,用户才会愿意打开AI。作者的策略是控制个体和地区,时间层面的固定效应来使这一选择变得随机。
作者排除了一拿到软件就开始使用的样本信息,因为作者需要用户使用AI前的信息来构建技能变量。
识别
作者使用生存分析模型研究问题。通常生存分析用于缺失数据,但这一情景并没有缺失数据的情况。作者使用这一方法是因为考虑到很多用户是在获客过程的中间打开的AI,作者希望利用到打开AI前后的数据变化,以获得更精准的估计。 作者假设变量T符合韦伯分布:

这是一个非线性模型,估计的系数较难解读。但基于韦伯分布的生存分析模型经过一些推导可以这样解读:
 我们可以看到,它变成了一个线性模型。我们关心的a可以被解读为打开AI对Log cruiseing time的影响。也可以解读为对cruise time比例的影响。
我们可以看到,它变成了一个线性模型。我们关心的a可以被解读为打开AI对Log cruiseing time的影响。也可以解读为对cruise time比例的影响。
确认假设正确性
作者在识别中做了两个假设,第一是控制一系列固定效应以后,是否打开AI的决策是大致随机的。使用logistics回归来处理二元选择变量问题:
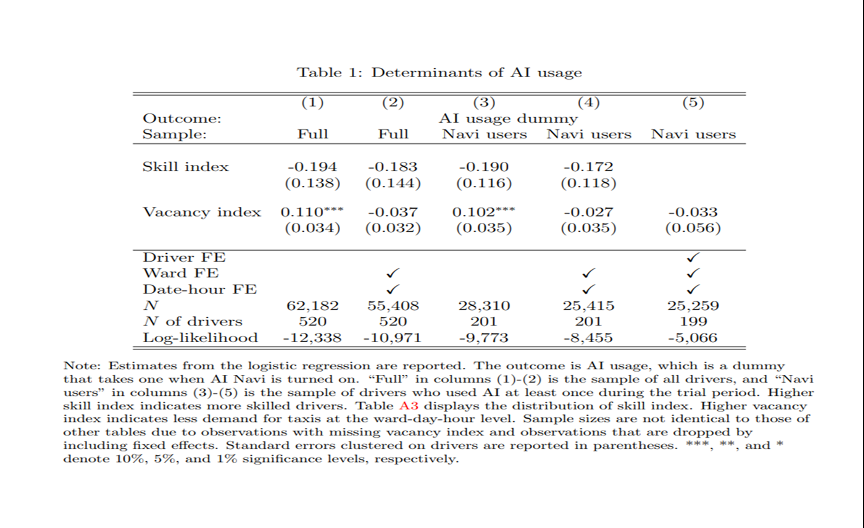
可以看到,控制固定效应后,个人的技能和所处的位置都不再决定个人是否使用AI。
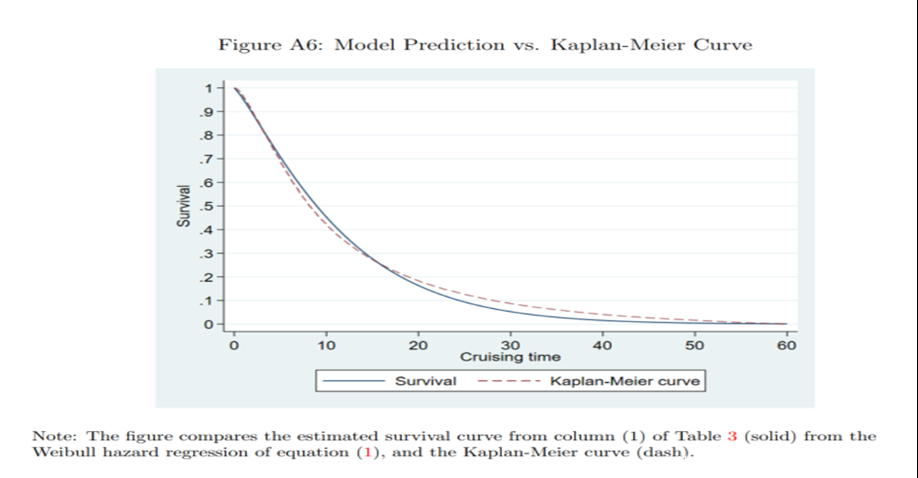
第二是T符合韦伯分布
作者使用不依赖分布假设的非参数估计方法Kaplan-Meier curve来估计生存函数,与假定韦伯分布的生存分析方法所导出的生存函数对比,发现拟合的很好。说明韦伯分布的假设是可以接受的。
主要结论
1)我们可以看到,AI的使用对技能的影响是正面的。在排除选择偏误以后,使用AI对获客时间是减少的作用。稳健性检验过后仍然成立。
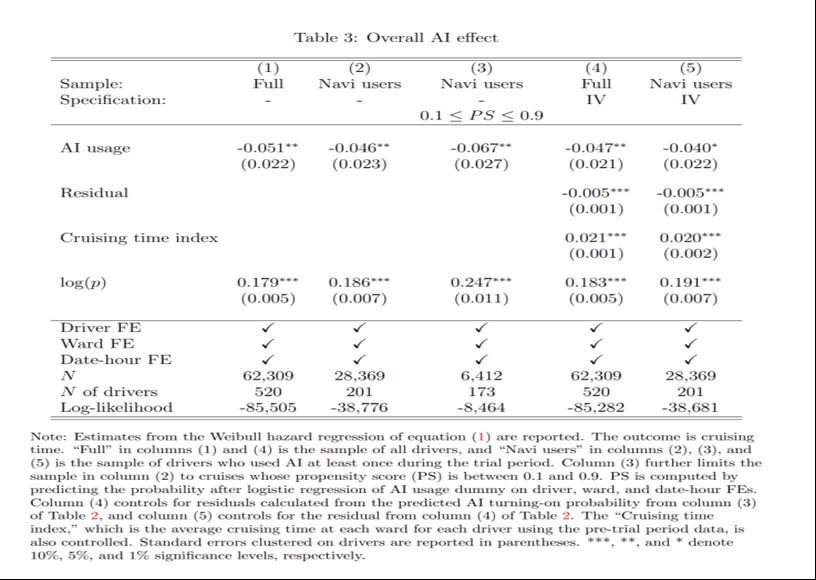
2)工具变量 作者使用工具变量解决仍存在的内生性考虑。
第一个工具变量是 上一个乘客下车的位置
如果该乘客在司机不熟悉的地方下车,会增加司机打开AI的概率,乘客下车的位置基本和司机没关系。但由于乘客在司机不熟悉的地方下车会增加司机获客时间,所以回归时加入该司机之前在这一地区获客的平均时间作为控制变量。
第二个工具变量是 司机之前使用AI的次数
因为之前使用AI会增加司机后来使用AI的概率,由于熟能生巧或者用户粘性,服从相关性条件
第一阶段回归使用Tobit模型,因为在一次获客过程的时间是有限的,也许时间长一点就会使用Ai,可以理解为缺失数据。
第二阶段,作者考虑控制第一阶段的残差,因为我们的模型是非线性的。实际上,在非线性模型里使用工具变量方面,并没有成熟的做法。这算是作者的一次尝试。
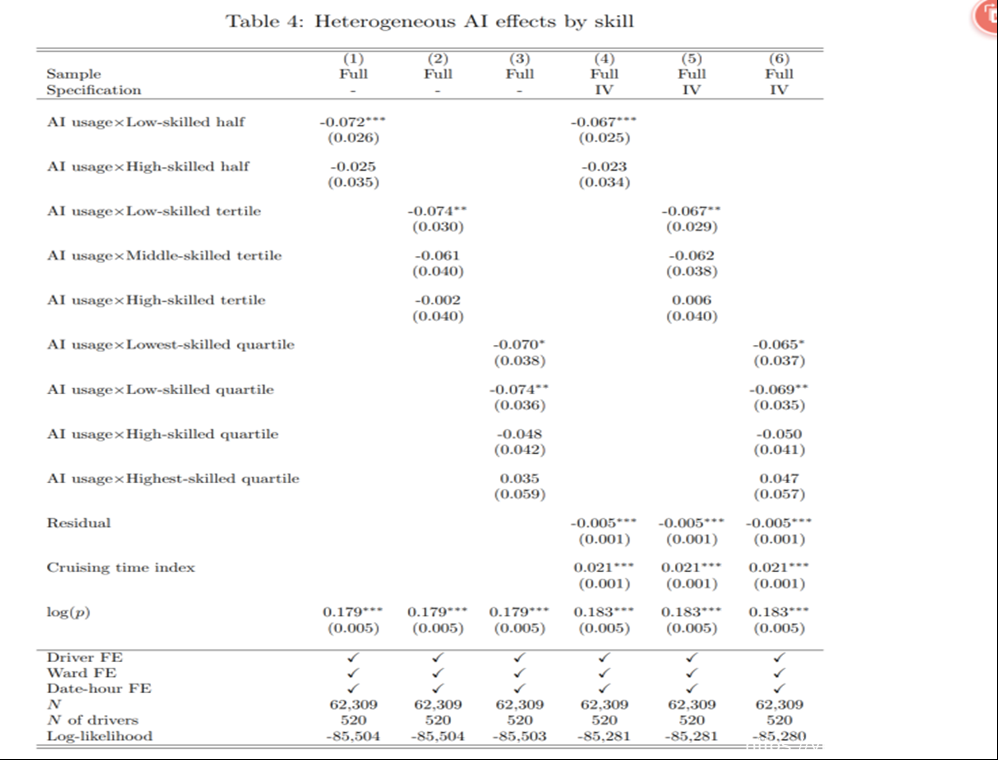
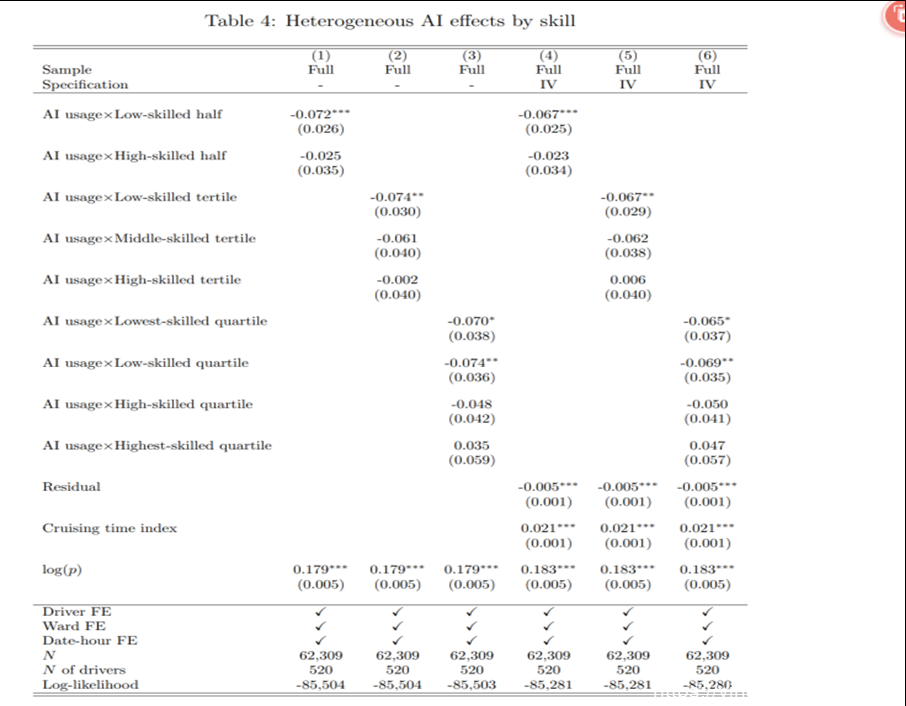
异质性分析。
我们可以看到,使用AI对低技能者有促进作用,对高技能者没有明显的促进或者抑制作用。






评论前必须登录!
立即登录 注册