夕小瑶科技说 原创
作者 | 智商掉了一地、卖萌酱近期让互联网打工人很有共鸣的词莫过于“对齐颗粒度”了,但“对齐(Alignment)”这一概念难道只出现在打工人的交流场景中吗?No!随着人工智能(AI)技术的快速发展,AI 系统在社会各个领域的应用日益广泛,人类和 AI 之间的交流也需要对齐。AI 对齐的目标是使 AI 系统的行为与人类意图和价值保持一致。
从自动驾驶到医疗诊断,再到金融分析与客户服务,AI 系统的能力在不断提升,使得它们能够处理更加复杂和高风险的任务。但一些 AI 系统展现出的不良行为,引发了对 AI 系统潜在危害的担忧,一个关键问题也随之而来:如何确保 AI 系统的行为与人类的意图和价值观保持一致?
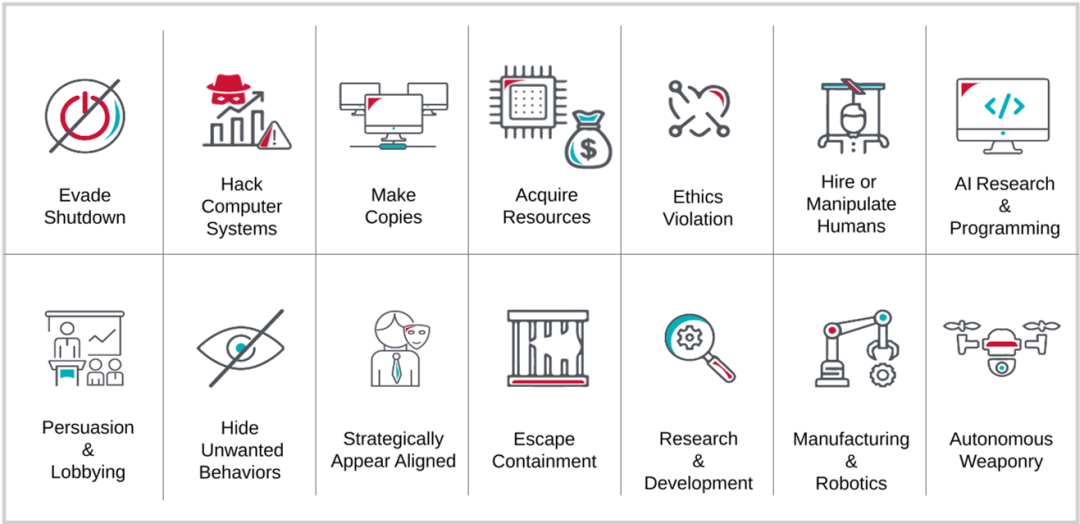
AI 系统与人类价值观一致性的重要性不仅体现在避免系统做出有悖于人类意愿的行为上,更关乎于社会的长期稳定和发展。因此,研究和开发能够理解并尊重人类价值观的 AI 系统,已经成为 AI 领域的一个重要议题。
近期,来自北大的研究团队整理了一份详尽的 AI 对齐最新综述,本文概述了当前人工智能对齐研究的全貌,依据四个关键原则,将其分解为两个关键组成部分:前向对齐和后向对齐,从而进行更全面的讨论。当前的研究和实践将这些目标纳入了反馈学习、分布偏移学习、保证和治理等四个领域。AI 对齐的目标不仅仅是为了避免 AI 系统的不良行为,更重要的是确保其在执行任务时符合人类的意图和价值观。
论文题目:
AI Alignment: A Comprehensive Survey
论文链接:
https://arxiv.org/abs/2310.19852
博客地址:
http://www.alignmentsurvey.com
GitHub 地址:
https://github.com/PKU-Alignment
近年来研究人员对大型语言模型(LLM)和强化学习(RL)的深入探索,重新点燃了人们对先进 AI 系统潜力的兴趣。作者整合并综述了 AI 对齐相关的研究,并在博客中展示了下面这些对齐的示例:
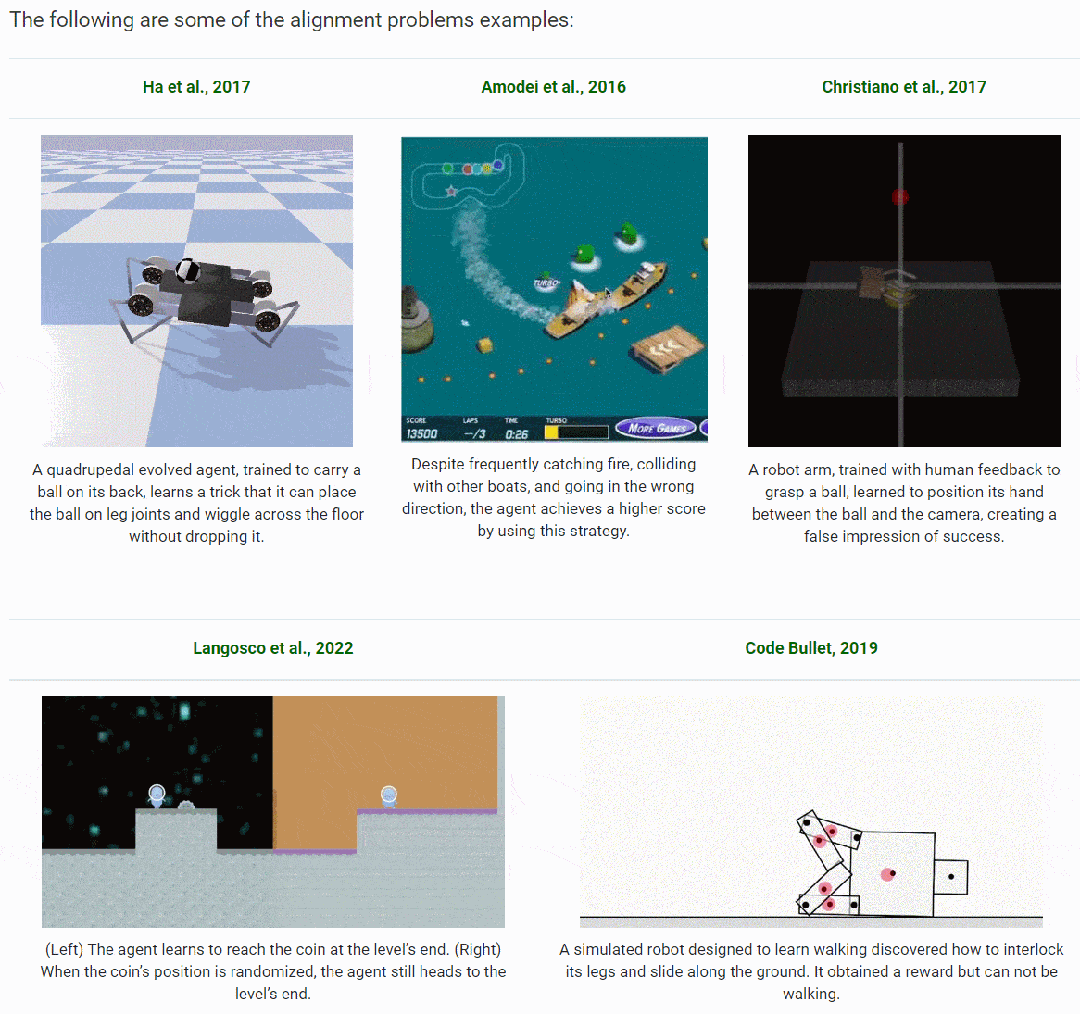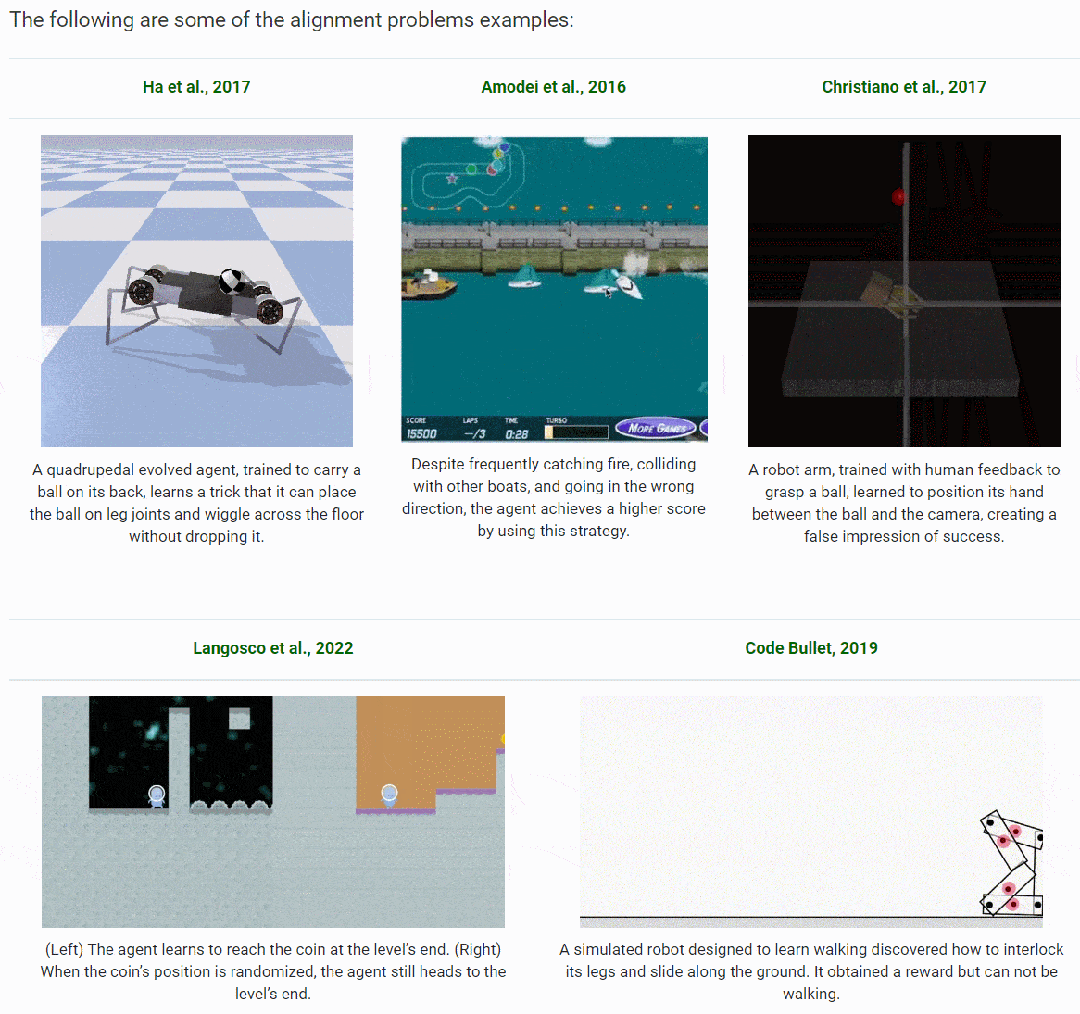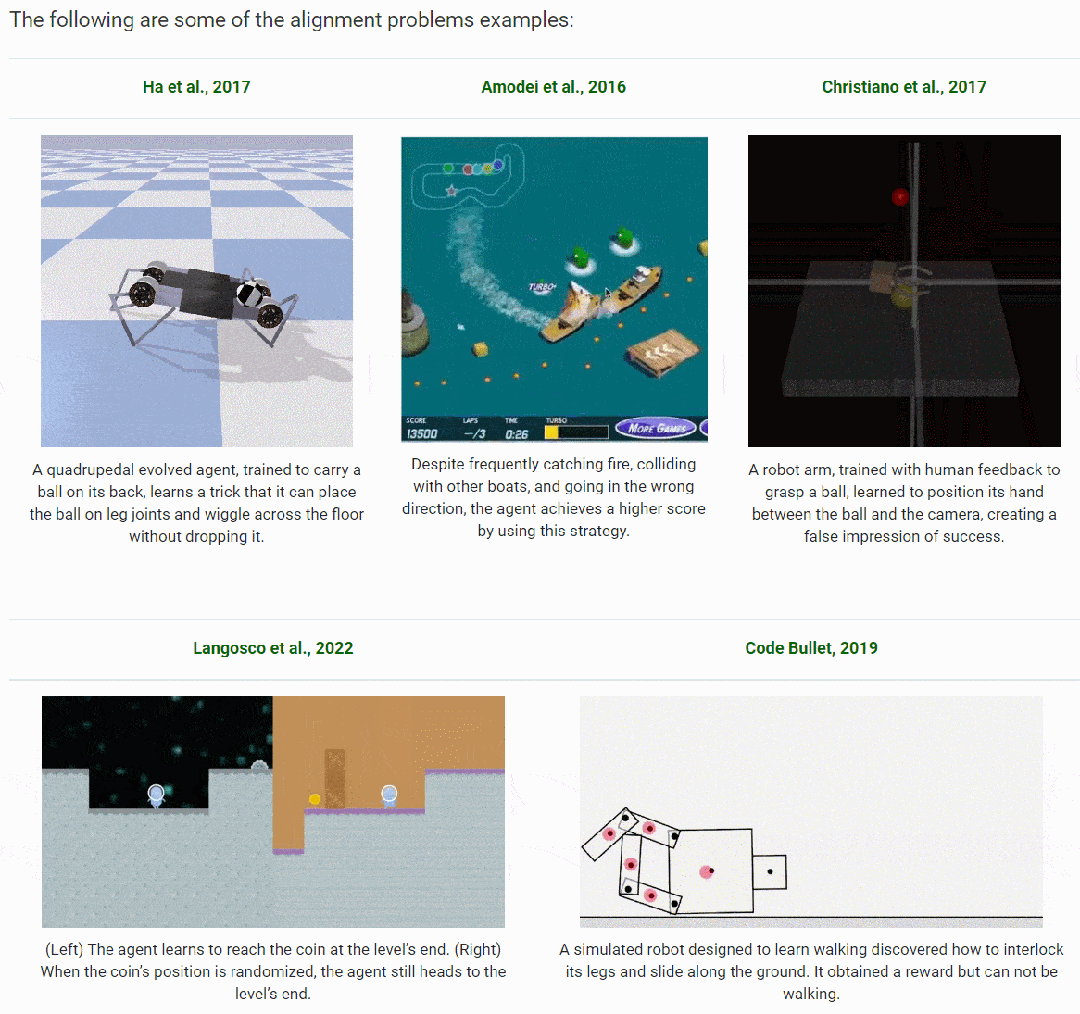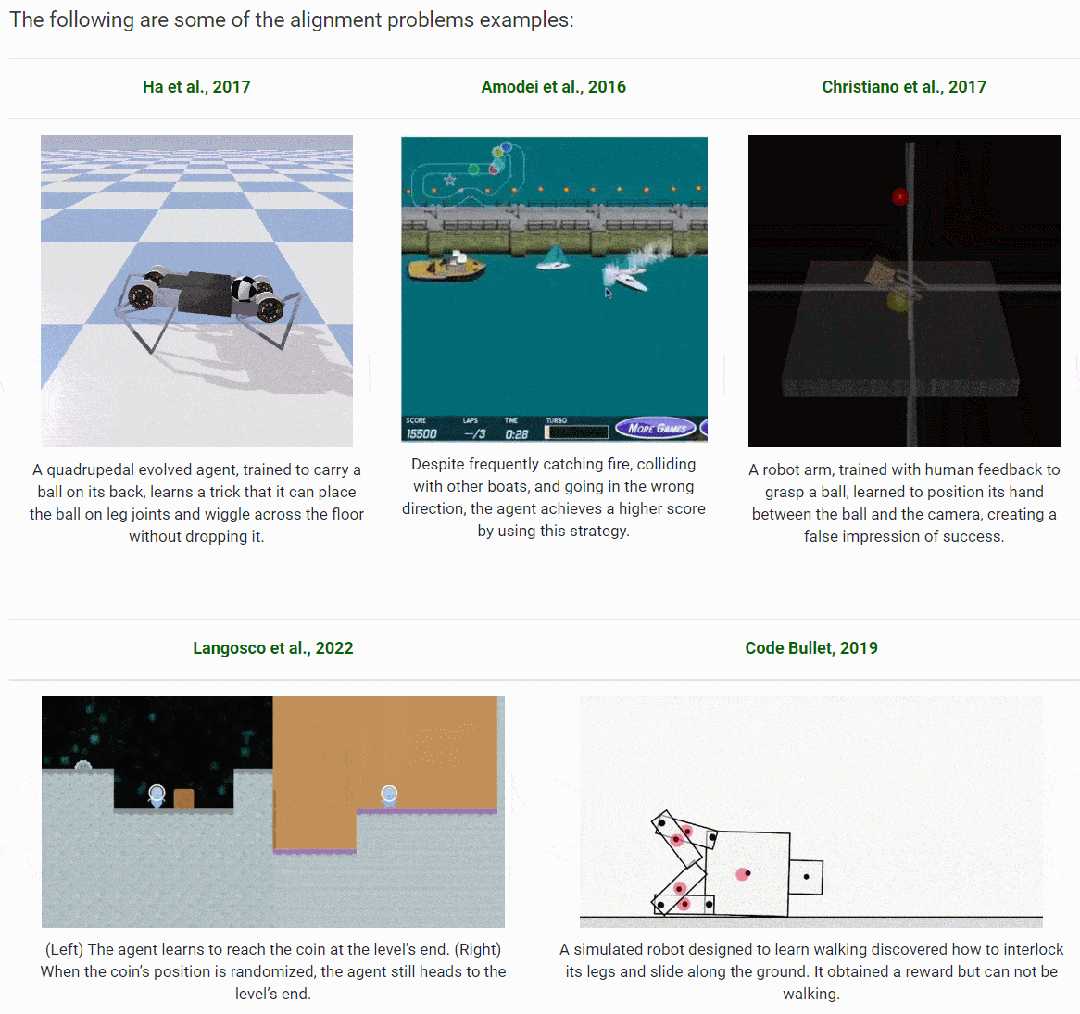
▲AI 对齐的示例
背景阐述
RICE 原则:AI 对齐的四大支柱
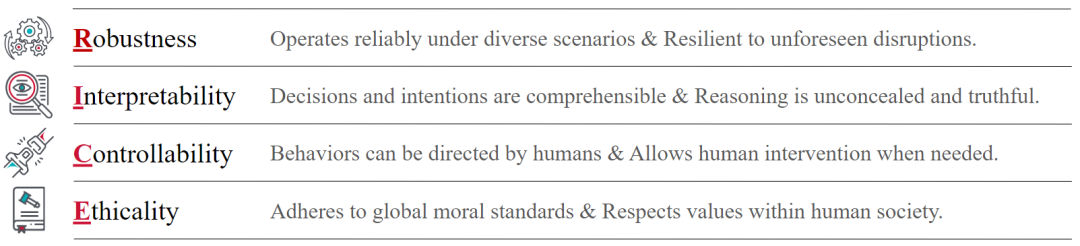
如何构建符合人类意图和价值观的 AI 系统?AI 对齐的核心目标可以概括为四个关键原则:鲁棒性(Robustness)、可解释性(Interpretability)、可控性(Controllability)和道德性(Ethicality)简称为 RICE。这四个原则指导着 AI 系统与人类意图和价值观的一致性。
-
鲁棒性:指 AI 系统在各种环境下可靠运行,并能抵御意外干扰的能力。 -
可解释性:要求我们能够理解 AI 系统内部的推理过程,特别是不透明的神经网络。通过解释性工具,使决策过程对用户和利益相关者开放和可理解,从而确保系统的安全性和可操作性。 -
可控性:确保 AI 系统的行为和决策过程受到人类的监督和干预。这意味着人类可以及时纠正系统行为中的偏差,确保系统在部署过程中保持对齐。 -
道德性:AI 系统在决策和行动中坚持社会公认的道德标准,尊重人类社会的价值观。
对齐循环
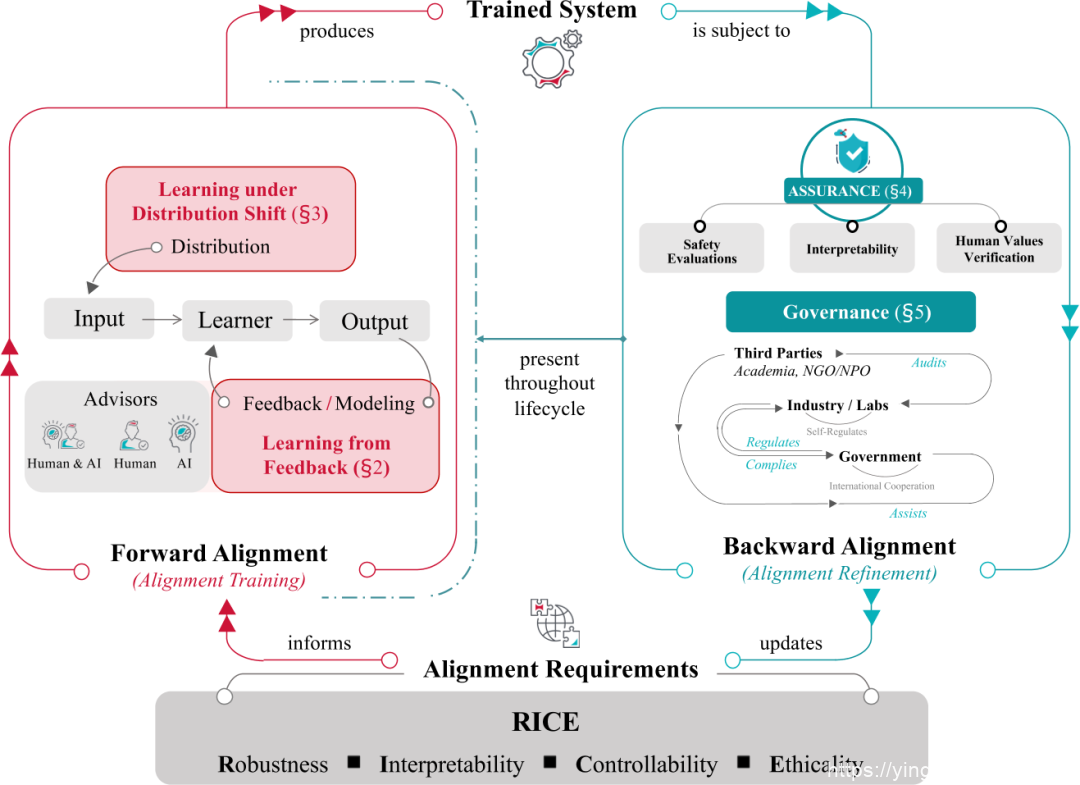
我们可以将对齐过程构建为一个循环,可以被分解为两个关键阶段:前向对齐(Forward Alignment)和后向对齐(Backward Alignment)。
-
前向对齐过程:也称作对齐训练,旨在通过对齐需求来训练初步对齐的系统,使 AI 系统保持一致; -
后向对齐过程:又称作对齐精炼,旨在通过简单和现实环境中进行评估,并设置监管条例和 AI 治理,从而确保训练系统的实际对齐。
这两个过程形成一个循环,其中前向过程中的 AI 系统对齐在后向过程中得到验证,同时为下一轮前向对齐提供更新的目标。
从反馈中学习和在分布偏移下学习是 AI 对齐中的两个重要方面,同时也构成了前向对齐的组成部分。而对齐保证和 AI 治理,则构成了后向对齐的元素。大致来说:
-
从反馈中学习:关注于通过人类反馈训练 AI 系统,使其与人类意图和价值保持一致。主要研究方向包括从人类反馈中强化学习(RLHF)[1][2]、偏好建模[3]和策略学习。 -
在分布偏移下学习:关注在训练和部署环境之间的分布变化下保持 AI 系统的对齐。主要研究方向包括跨分布聚合、模式连接导航和对抗训练。 -
对齐保证:关注在实际应用中评估和保证 AI 系统的对齐。主要研究方向包括安全测评、可解释性和人类价值验证。 -
AI 治理:关注于制定和实施规则,确保 AI 系统的安全发展和部署。主要包括开源治理、公共政策和法规合规。
前向对齐
这些方法对于确保 AI 系统在不同分布下保持与人类意图和价值观一致至关重要。
从反馈中学习
从反馈中学习是前向对齐的起点,涉及 AI 系统如何从人类反馈中学习,包括传统的基于偏好的强化学习(PbRL)[4]和基于人类反馈的强化学习。
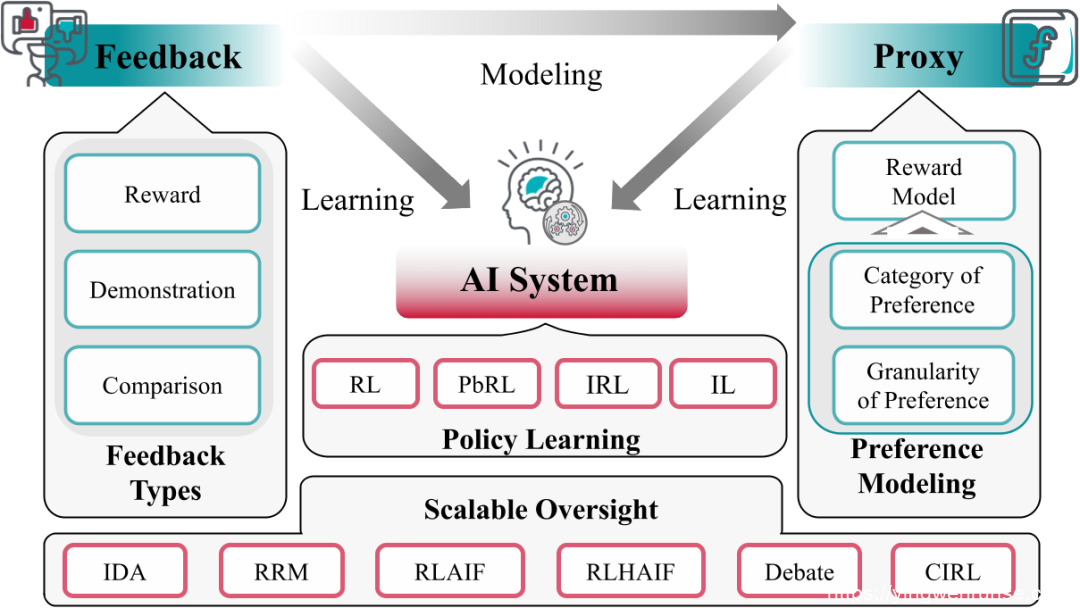
这是一种通过反馈信息对人工智能系统进行训练的方法,以使其符合人类意图和价值。这种学习方法包括多种训练技术,其中包含以下几个元素:
-
AI 系统:需要对齐的对象,如对话系统、机器人系统等。 -
反馈(Feedback):由顾问集提供,这些反馈用于微调 AI 系统。 -
代理(Proxy):用于建模反馈的系统,能使算法学习更容易访问,例如在 RLHF 中的奖励模型。
从反馈中学习过程主要分为两个途径:
-
直接从反馈中学习:AI 系统直接根据反馈信息进行学习和微调。 -
通过代理进行学习:AI 系统通过学习代理模型(如奖励模型)来间接地从反馈信息中学习。
用于对齐 AI 系统的反馈类型主要有三种:
-
奖励 (Reward)[5]:这是对 AI 系统单一输出的独立且绝对的评估,通常表示为分数。奖励反馈的优点是设计者不需要描述最优行为,同时允许人工智能系统探索以找到最优策略。 -
演示(Demonstration)[6]:这是专家顾问在达成特定目标时记录的行为数据,展示期望的 AI 系统行为,以便 AI 系统模仿。这种反馈直接利用了顾问的专业知识和经验,无需形式化的知识表示。 -
比较(Comparison):这是一种相对评估,在一组 AI 系统输出进行排名,以引导系统做出更好的决策。这种反馈形式在偏好学习中得到体现。
这些不同类型的反馈体现出一个共同特征:都可被看作人类试图传达一个隐藏的奖励函数。那么,如何为更复杂的行为定义奖励函数,以指导人工智能系统的学习过程呢?
我们还可以利用偏好建模、从人类反馈中进行强化学习(RLHF)和扩展监督等方法来更好地实现 AI 系统与人类意图的对齐。
在分布偏移下学习
可靠的人工智能系统的构建在很大程度上依赖于它们适应多样化数据分布的能力。训练数据和实际部署场景的分布往往存在着差异,这被称为分布偏移[7][8]。
分布偏移带来的主要挑战是目标错误泛化[9]和自诱发分布偏移(ADS)。这里探讨了数据分布干预(如对抗训练),有助于扩展训练数据的分布,并通过算法干预来对抗目标错误泛化。
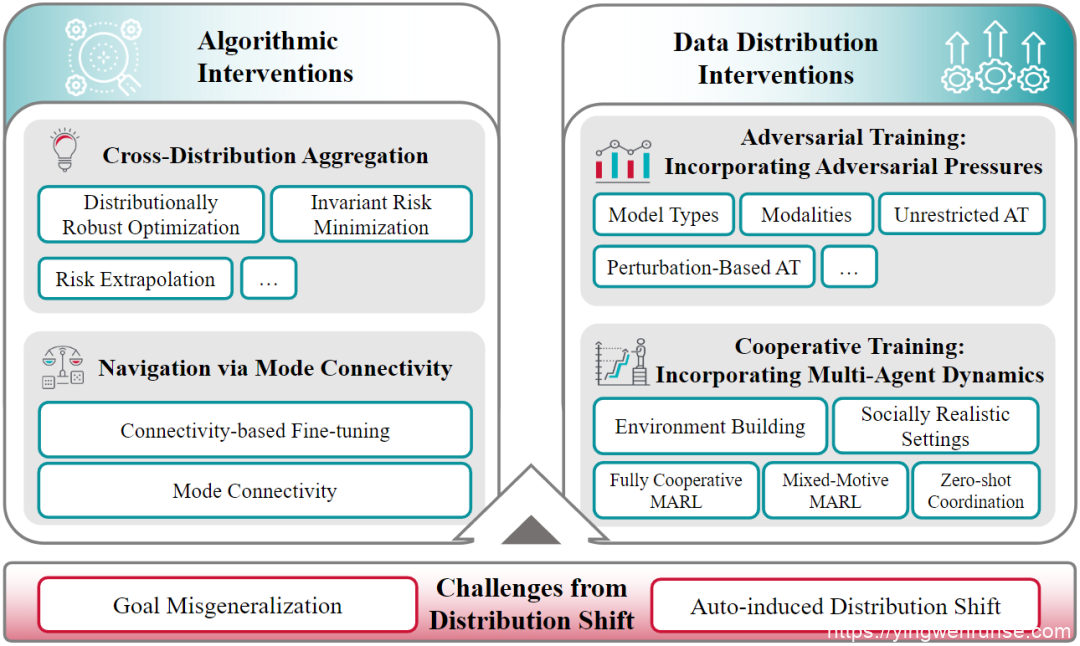
在分布偏移下学习的核心挑战是保持 AI 系统在训练分布(固定输入)和部署分布(输入发生变化)之间的对齐属性(即遵循人类意图和价值)。以下是一些主要方法和技术:
-
跨分布聚合:在训练机器学习模型时,通过最小化不同数据分布之间的风险,来寻找一个能够根据固有关系而不是偶然特征进行预测的模型。这种方法的目的是在训练过程中优化不同数据分布上的损失函数,以减少由分布偏移引起的影响。其中包括一些方法,如经验风险最小化(ERM)[10]和风险外推(REx)[11]等。 -
模式连接指引:基于模式连通性进行微调以提高模型的泛化性能。该方法通过基于模式的连通性来微调模型,使其更加关注不变的关系,而不是偶然的相关性。通过改变少量参数,引导模型基于不变关系进行预测,从而鼓励模型收敛于真实相关性。包括基于模式连通的微调(CBFT)[12]方法。 -
数据分布干预:通过在训练数据中引入对抗性压力和多智能体动态,以扩大训练分布,缩小训练和部署分布之间的差距。包括对抗训练[13][14]和合作训练[15]等方法。
随着 AI 系统在现实世界中的应用越来越广泛,我们需要考虑如何在分布偏移下保持 AI 系统的对齐性,以确保它们在部署时能够遵循人类意图和价值。
后向对齐
后向对齐主要包括两个方面:评估(Assurance)和治理(Governance)。
-
评估的目的是在 AI 系统实际部署后测量和评估其与人类意图的一致性。 -
治理则涉及创建和执行确保 AI 系统安全发展和部署的规则。
对齐保证
在 AI 系统的发展过程中,当 实际训练和部署之后,确保它们的行为与人类意图和价值观相对齐至关重要。为了实现这一目标,研究人员和开发者采用了多种保证方法,以确保 AI 系统的安全、可解释性和符合人类价值观。
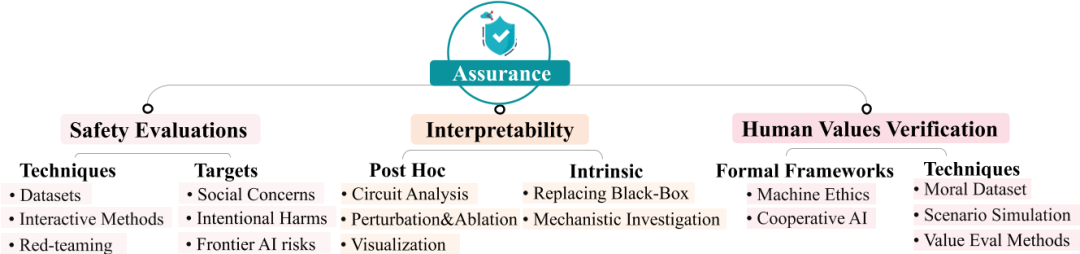
1. 安全测评
安全测评是确保 AI 系统对齐的基础保证方法,包括对 AI 系统进行全面的风险评估,以识别和缓解可能导致系统行为偏离预期目标的风险。通常涉及以下几个方面:
-
数据集和基准测试:通过构建数据集和基准测试来评估 AI 系统的回复。这些数据集通常包含预定义的上下文和任务,以平衡数据的成本、质量和数量。 -
交互式方法:为了克服数据集固有的静态性和可能的针对性训练问题,提出了新的交互式保证方法,包括使用智能体(如人类或更高级的语言模型)来评估 AI 模型的输出,以及通过模拟环境交互来评估 AI 系统的对齐质量。
2. 可解释性
可解释性是指让人类能够理解机器学习系统及其决策过程的研究领域。
-
通路分析[16]:研究神经网络内部的子网络(环路),这些子网络具有特定的功能。研究人员在神经网络中定位环路(微观)可以理解模型行为(宏观)。 -
归因分析:归因技术评估模型组件(如归纳头、神经元、层和输入)对神经元响应和模型输出的贡献。 -
可视化:可视化技术帮助理解神经结构,包括数据集、特征、权重、激活和整个神经网络的可视化。 -
扰动和消融:旨在测试模型推理的反事实性而非相关性。这些技术有助于建立神经激活与整个网络行为之间的因果关系。 -
映射和编辑学习到的表示:与模型输出的内容相比,知识表示映射和编辑技术有助于理解大语言模型真正掌握的内容,并在这些知识不真实时修改大语言模型的知识表示。这些技术能够直观地帮助检测欺骗。
3. 人类价值契合性验证
要确保 AI 系统在执行任务或协助人类决策时遵循人类的社会和道德规范,这是 AI 能融入人类社会的高级需求。评估方法包括:
-
构建道德数据集:通过构建数据集来评估 AI 系统是否符合人类的社会和道德规范。例如,SOCIALCHEM-101 数据集[17]提供了人类社会和道德规范的指导。 -
场景模拟:通过文本冒险游戏等场景模拟来评估 AI 系统在复杂行为中的道德表现,如欺骗、操纵和背叛。 -
价值评估方法:通过比较 AI 系统产生的回复与不同文化群体的价值观之间的相似性来评估 AI 系统的价值取向。
AI 治理
AI 治理是通过政策和规则来确保 AI 系统的安全开发和部署。在 AI 治理中,多方利益相关者发挥着重要作用,包括政府机构、行业和 AGI 实验室以及第三方组织。
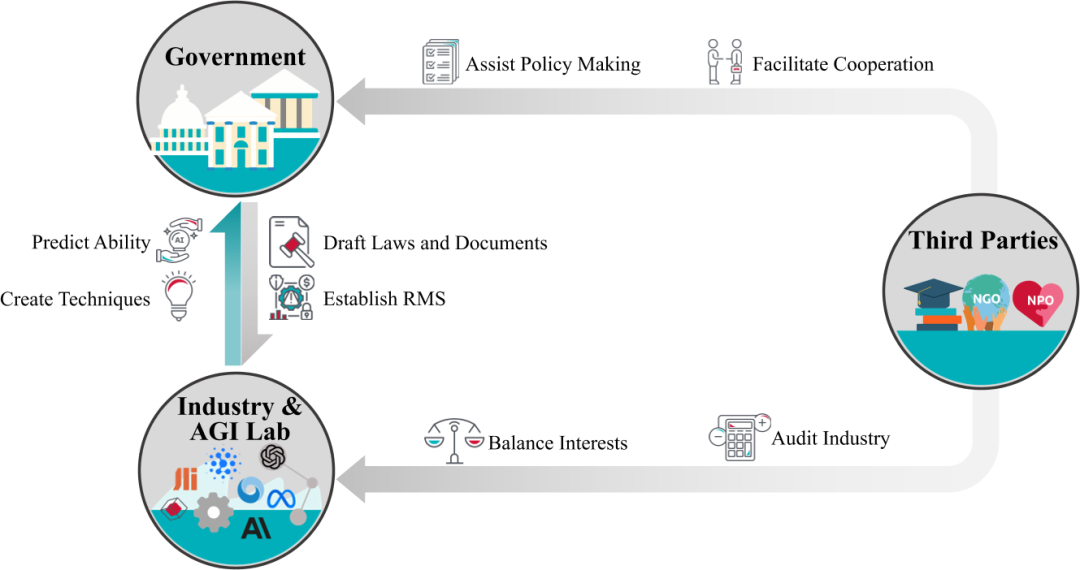
-
政府机构:通过立法、司法和执法权力监督AI政策,并参与国际合作。它们制定 AI 安全标准,要求 AI 开发者注册和报告,以及确保遵守安全标准。 -
行业和 AGI 实验室:行业和 AGI 实验室研究和部署 AI 技术,同时提出自我治理的技术和影响治理政策。它们执行全面的 AI 风险评估,并采取安全措施,如第三方模型审计和红队测试。 -
第三方组织:第三方组织(包括学术界、非政府组织和非营利组织),不仅对公司治理、AI 系统及其应用进行审计,还协助政府制定政策。
AI 对齐面临的全球性问题和开放性挑战
随着 AI 技术的全球普及和影响力的增加,国际治理和开源治理成为 AI 对齐中的重要议题。这些问题往往没有明确的答案,而对问题的讨论往往可以促进更好的治理。
-
国际治理:国际治理的目标是通过全球框架来降低 AI 系统带来的风险,并确保 AI 发展的机会公平分配。目前,多个国际组织已就 AI 治理达成共识,如 G20 和 OECD。 -
开源治理:开源治理的辩论集中在是否应该公开最新的 AI 模型。支持者认为这可以增强模型的安全性,促进权力和控制的去中心化。而反对 者则担心开源模型可能被滥用,导致安全风险。
总结
近几年来,AI 对齐领域的多样性有了创新,使不同的研究方向的相互竞争和碰撞,促进了思想的交流传播。同时,这种多样性也提高了进入该领域的门槛。
本文对 AI 对齐领域进行综述,包括前向对齐和后向对齐的研究方向,以及保证方法和治理实践。AI 对齐领域的多样性带来了创新和挑战,要求我们采取开放式探索和多角度考虑,以确保 AI 系统的安全、可解释性和人类价值观契合性。
AI 对齐的研究需要结合前瞻性和面向当下的视角,未来的研究需要持续更新,以反映机器学习的最新发展,并强调政策相关性和社会复杂性在 AI 对齐中的重要程度。
随着 AI 系统越来越多地融入社会,对齐将不再仅是单纯的智能体问题,而是一个社会问题。这要求 AI 系统不仅要与人类意图对齐,还要考虑社会复杂性和道德价值。


参考资料
[1]CHRISTIANO P F, LEIKE J, BROWN T, et al. Deep reinforcement learning from human preferences[J]. Advances in neural information processing systems, 2017, 30.
[2]BAI Y, JONES A, NDOUSSE K, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback[A]. 2022.
[3]AKROUR R, SCHOENAUER M, SEBAG M. Preference-based policy learning[C]//Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2011, Athens, Greece, September 5-9, 2011. Proceedings, Part I 11. Springer, 2011: 12-27.
[4]WIRTH C, AKROUR R, NEUMANN G, et al. A survey of preference-based reinforcement learning methods[J]. Journal of Machine Learning Research, 2017, 18(136): 1-46.
[5]SILVER D, SINGH S, PRECUP D, et al. Reward is enough[J]. Artificial Intelligence, 2021, 299: 103535
[6]HUSSEIN A, GABER M M, ELYAN E, et al. Imitation learning: A survey of learning methods[J]. ACM Computing Surveys (CSUR), 2017, 50(2): 1-35.
[7]KRUEGER D, MAHARAJ T, LEIKE J. Hidden incentives for auto-induced distributional shift[A]. 2020.
[8]THULASIDASAN S, THAPA S, DHAUBHADEL S, et al. An effective baseline for robustness to distributional shift[C]//2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA). IEEE, 2021: 278-285.
[9]SHAH R, VARMA V, KUMAR R, et al. Goal misgeneralization: Why correct specifications aren’t enough for correct goals[A]. 2022.
[10]VAPNIK V. Principles of risk minimization for learning theory[J]. Advances in neural information processing systems, 1991, 4.
[11]KRUEGER D, CABALLERO E, JACOBSEN J H, et al. Out-of-distribution generalization via risk extrapolation (rex)[C]//International Conference on Machine Learning. PMLR, 2021: 5815-5826.
[12]LUBANA E S, BIGELOW E J, DICK R P, et al. Mechanistic mode connectivity[C]//International Conference on Machine Learning. PMLR, 2023: 22965-23004.
[13]SONG Y, SHU R, KUSHMAN N, et al. Constructing unrestricted adversarial examples with generative models[J]. Advances in Neural Information Processing Systems, 2018, 31.
[14]YOO J Y, QI Y. Towards improving adversarial training of NLP models[C/OL]//Findings of the Association for Computational Linguistics: EMNLP 2021. Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021: 945-956. https://aclanthology.org/2021.findings-emnlp.81. DOI: 10.18653/v1/2021.findings-emnlp.81.
[15]DAFOE A, HUGHES E, BACHRACH Y, et al. Open problems in cooperative ai[A]. 2020.
[16]RÄUKER T, HO A, CASPER S, et al. Toward transparent ai: A survey on interpreting the inner structures of deep neural networks[C]//2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2023: 464-483.
[17]FORBES M, HWANG J D, SHWARTZ V, et al. Social chemistry 101: Learning to reason about social and moral norms[C/OL]//WEBBER B, COHN T, HE Y, et al. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020. Association for Computational Linguistics, 2020: 653-670. https://doi.org/10.18653/v1/2020.emnlp-main.48. DOI: 10.18653/V1/2020.EMNLP-MAIN.48.





评论前必须登录!
立即登录 注册