【导读】可解释人工智能(Explainable Artificial Intelligence)旨在于具备可为人类所理解的功能或运作机制,拥有透明度, 是当前AI研究的热点,是构建和谐人机协作世界必要的条件,是构建负责任人工智能的基础。最近来自法国西班牙等8家机构12位学者共同发表了关于可解释人工智能XAI最新进展的综述论文《Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI》,共67页pdf调研了402篇文献,讲解了最新可解释人工智能的进展,集大成者,梳理了XAI的体系,并提出构建负责任人工智能的内涵,非常具有指引性。
摘要
在过去的几年里,人工智能(AI)取得了显著的发展势头,在不同领域的许多应用中它可能会带来最好的预期。当这种情况发生时,整个社区都面临可解释性的障碍,这是人工智能技术的一个内在问题,它是由次象征主义(模型例如集成算法或深层神经网络)带来的,而这些在人工智能的最上一次高潮中是不存在的。这个问题背后的范例属于所谓的可解释AI (XAI)领域,它被认为是AI模型实际部署的一个关键特性。本文综述了XAI领域的现有文献,并对未来的研究方向进行了展望。我们总结了在机器学习中定义可解释性的前期工作,建立了一个新的定义,它涵盖了先前的概念命题,主要关注可解释性所关心的受众。然后,我们提出并讨论了与不同机器学习模型的可解释性相关的最近贡献的分类,包括那些旨在建立第二种体系的深度学习方法。这篇文献分析为XAI面临的一系列挑战提供了背景,比如数据融合和可解释性之间的十字路口。我们构建了负责任的人工智能的概念,即一种以公平、模型可解释性和问责性为核心的在真实组织中大规模实施人工智能方法的方法。最终目标是为XAI的新来者提供参考资料,以促进未来的研究进展,同时也鼓励其他学科的专家和专业人员在他们的活动领域拥抱AI的好处,而不是因为它缺乏可解释性而事先有任何偏见。
关键词: 可解释人工智能,机器学习,深度学习,数据融合,可解释性,可理解性,透明性,隐私,公平性,可问责性,负责任的人工智能。
目录
1. 引言
2. 可解释性: 是什么,为什么,什么目标,怎么做?
3. 透明机器学习模型
4. 机器学习模型的后解释技术:分类法、浅层模型和深度学习
5. XAI:机遇、挑战和研究需求
6. 走向负责任的人工智能:人工智能、公平、隐私和数据融合的原则
7. 结论和展望
1. 引言
人工智能(AI)是许多采用新信息技术的活动领域的核心。人工智能的起源可以追溯到几十年前,人们对于智能机器具有学习、推理和适应能力的重要性有着明确的共识。正是凭借这些能力,人工智能方法在学习解决日益复杂的计算任务时达到了前所未有的性能水平,这对人类社会[2]的未来发展至关重要。近来,人工智能系统的复杂程度已经提高到几乎不需要人为干预来设计和部署它们。当来自这些系统的决策最终影响到人类的生活(例如,医学、法律)时,就有必要了解这些决策是如何由人工智能方法[3]提供的。
最早的人工智能系统是很容易解释的,过去的几年见证了不透明的决策系统的兴起,比如深度神经网络(DNNs)。深度学习(DL)模型(如DNNs)的经验成功源于高效的学习算法及其巨大的参数空间的结合。后一个空间由数百层和数百万个参数组成,这使得DNNs被认为是复杂的黑盒模型[4]。black-box-ness的反义词是透明性,即以寻求对模型工作机理的直接理解。
随着黑箱机器学习(ML)模型越来越多地被用于在关键环境中进行重要的预测,人工智能[6]的各个利益相关者对透明度的要求也越来越高。危险在于做出和使用的决策不合理、不合法,或者不允许对其行为进行详细的解释。支持模型输出的解释是至关重要的,例如,在精准医疗中,为了支持诊断[8],专家需要从模型中获得远比简单的二进制预测多得多的信息。其他例子包括交通、安全、金融等领域的自动驾驶汽车。
一般来说,考虑到对合乎道德的人工智能[3]日益增长的需求,人类不愿采用不能直接解释、处理和信任的[9]技术。习惯上认为,如果只关注性能,系统将变得越来越不透明。从模型的性能和它的透明性[10]之间的权衡来看,这是正确的。然而,对一个系统理解的提高可以导致对其缺陷的修正。在开发ML模型时,将可解释性考虑为额外的设计驱动程序可以提高其可实现性,原因有三:
-
可解释性有助于确保决策的公正性,即检测并纠正训练数据集中的偏差。
-
可解释性通过强调可能改变预测的潜在对抗性扰动,促进了稳健性的提供。
-
可解释性可以作为一种保证,即只有有意义的变量才能推断出输出,即,以确保模型推理中存在真实的因果关系。
这意味着,为了考虑实际,系统的解释应该要么提供对模型机制和预测的理解,要么提供模型识别规则的可视化,要么提供可能扰乱模型[11]的提示。
为了避免限制当前一代人工智能系统的有效性,可解释人工智能(XAI)[7]建议创建一套ML技术,1) 产生更多可解释的模型,同时保持高水平的学习性能(如预测准确性),2) 使人类能够理解、适当信任和有效管理新一代人工智能伙伴。XAI还借鉴了社会科学的[12],并考虑了解释心理学。
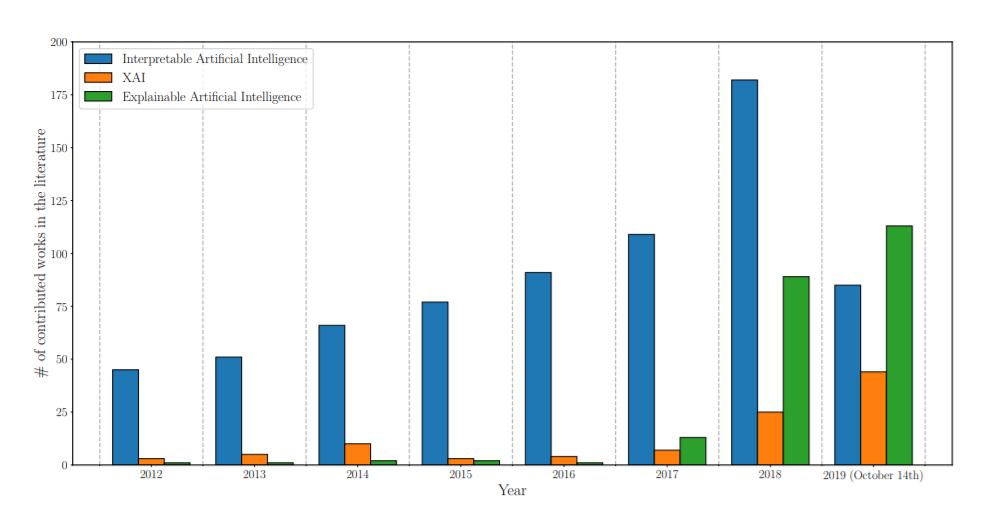
图1: 过去几年中,标题、摘要和/或关键词涉及XAI领域的出版物总数的变化。通过提交图中所示的查询从Scopus R数据库检索到的数据(2019年10月14日)。值得注意的是,随着时间的推移,对可解释的AI模型的潜在需求(这符合直觉,因为在许多场景中,可解释性是一种要求),但直到2017年,解释AI模型的技术兴趣才渗透到整个研究领域。
这篇综述的其余部分的结构如下:首先,第2节和其中的子节围绕AI中的可解释性和可解释性展开了关于术语和概念的讨论,最后得出前面提到的可解释性的新定义(第2.1和2.2小节),以及从XAI的角度对ML模型进行分类和分析的一般标准。第3节和第4节回顾了ML模型(分别是透明模型和事后技术)的XAI的最新发现,它们构成了上述分类中的主要部分。同时,我们也回顾了这两种方法的混合,以达到XAI。在第5节中讨论了各种方法之间的协同作用的好处和注意事项,在这里,我们提出了对一般挑战的展望和需要谨慎对待的一些后果。最后,第6节阐述了负责任的人工智能的概念。第7节总结了调查,目的是让社区参与到这一充满活力的研究领域中来,这一领域有可能影响社会,特别是那些逐渐将ML作为其活动核心技术的部门。
2. 可解释性: 是什么,为什么,怎么做?
在继续我们的文献研究之前,我们可以先建立一个共同的观点来理解在AI的可解释性这个术语,更具体地说是ML中的含义。这确实是本节的目的,即暂停对这个概念的大量定义(什么?),讨论为什么可解释性在AI和ML中是一个重要的问题(为什么?目的何在?),并介绍XAI方法的一般分类,这将推动此后的文献研究(如何?)。
2.1 术语说明
-
Understandability(或等同地,intelligibility)指的是一个模型的特征,使人理解其功能——模型如何工作——而不需要解释其内部结构或模型内部处理数据[18]的算法方法。
-
Comprehensibility: 在ML模型中,可理解性是指学习算法以人类可理解的方式表示其已学知识的能力[19,20,21]。这种模型可理解性的概念源于Michalski[22]的假设,即“计算机归纳的结果应该是对给定实体的符号描述,在语义和结构上类似于人类专家可能产生的观察相同实体的结果。”这些描述的组成部分应作为单一的‘信息块’可理解,可直接用自然语言解释,并应以综合方式将定量和定性概念联系起来”。由于难以量化,可理解性通常与模型复杂度[17]的评估联系在一起。
-
Interpretability可解释性是指以可理解的语言向人类解释或提供意义的能力。
-
Explainability可解释性与作为人类和决策者之间的接口的解释概念相关,同时,这也是决策者的准确代理,也是人类可以理解的[17]。
-
Transparency 透明度:如果一个模型本身是可以理解的,那么它就被认为是透明的。由于模型具有不同程度的可理解性,因此第3节中的透明模型分为三类: 可模拟模型、可分解模型和算法透明模型[5]。
2.2 什么?
虽然这可能被认为超出了本文的范围,但值得注意的是在哲学领域[23]中围绕一般解释理论展开的讨论。在这方面已经提出了许多建议,建议需要一种普遍的、统一的理论来近似解释的结构和意图。然而,在提出这样一个普遍的理论时,没有人经得起批评。就目前而言,最一致的想法是将不同的解释方法从不同的知识学科中融合在一起。在处理人工智能的可解释性时也发现了类似的问题。从文献中似乎还没有一个共同的观点来理解什么是可解释性或可解释性。然而,许多贡献声称是可解释(interpretable)模型和技术的成就增强了可解释性(explainability).
为了阐明这种缺乏共识的情况,我们不妨以D. Gunning在[7]中给出的可解释人工智能(XAI)的定义作为参考起点:
“XAI将创造一套机器学习技术,使人类用户能够理解、适当信任并有效管理新一代人工智能合作伙伴。
这个定义结合了两个需要提前处理的概念(理解和信任)。然而,它忽略了其他目的,如因果关系、可转移性、信息性、公平性和信心等,从而激发了对可解释AI模型的需求[5,24,25,26]。
进一步修正,我们给出explainable AI的定义:
给定一个受众,一个可解释的人工智能是一个产生细节或理由使其功能清晰或容易理解的人工智能。
这个定义在这里作为当前概述的第一个贡献,隐含地假设XAI技术针对当前模型的易用性和清晰性在不同的应用目的上有所恢复,比如更好地让用户信任模型的输出。
2.3 为什么?
如引言所述,可解释性是人工智能在实际应用中面临的主要障碍之一。无法解释或完全理解最先进的ML算法表现得如此出色的原因是一个问题,它的根源有两个不同的原因,如图2所示。
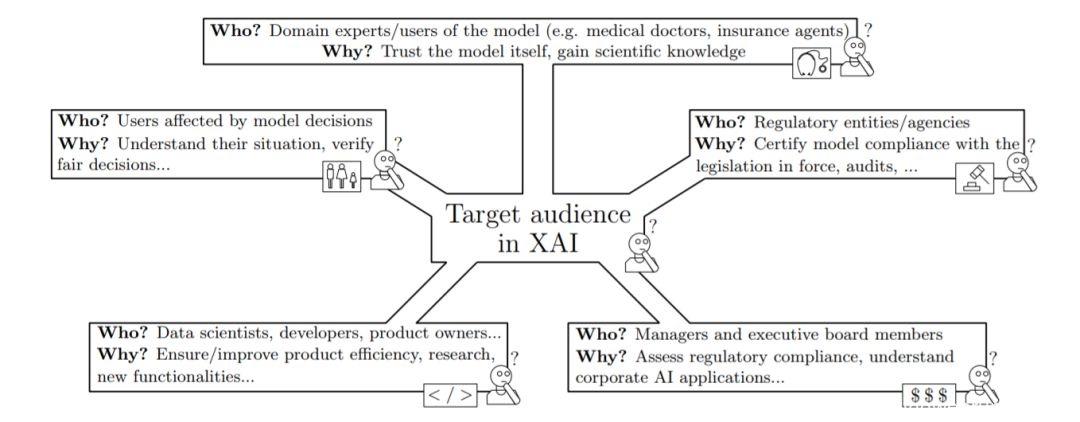
图2: 图中显示了在ML模型中由不同的用户配置文件寻找的可解释性的不同目的。它们有两个目标:模型理解的需要和法规遵从性。
2.4 什么目标?
到目前为止,围绕XAI的研究已经揭示出了不同的目标,以便从一个可解释的模型的实现中得出结论。几乎没有一篇被调研的论文在描述一个可解释的模型所要求的目标上是完全一致的。尽管如此,所有这些不同的目标都可能有助于区分特定的ML可解释性的目的。不幸的是,很少有人试图从概念的角度来界定这些目标[5、13、24、30]。我们现在综合并列举这些XAI目标的定义,以便为这篇综述涵盖的所有论文确定第一个分类标准:
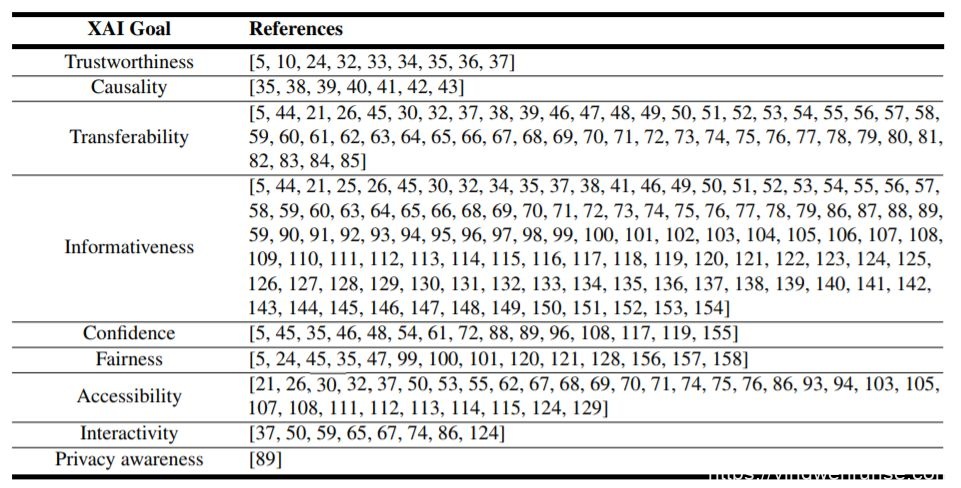
图3. 可解释AI不同的度量维度
-
可信赖性Trustworthiness:一些作者同意将可信赖性作为可解释AI模型的主要目标[31,32]。然而,根据模型诱导信任的能力将模型声明为可解释的可能并不完全符合模型可解释性的要求。可信度可以被认为是一个模型在面对给定问题时是否会按预期行事的信心。虽然它肯定是任何可解释模型的一个属性,但它并不意味着每一个值得信任的模型都可以被认为是可解释的,可信度也不是一个容易量化的属性。信任可能远远不是可解释模型的唯一目的,因为两者之间的关系,如果达成一致,并不是相互的。在综述的论文中,有一部分提到了信任的概念。但是,如表1所示,它们在最近与XAI相关的贡献中所占的份额并不大。
-
因果关系Causality:可解释性的另一个常见目标是发现数据变量之间的因果关系。一些作者认为,可解释的模型可能简化了寻找关系的任务,如果它们发生,可以进一步测试所涉及的变量之间更强的因果关系[159,160]。从观测数据推断因果关系是一个随着时间的推移已经被广泛研究的领域[161]。正如从事这一主题的社区所广泛承认的那样,因果关系需要一个广泛的先验知识框架来证明所观察到的影响是因果关系。ML模型只发现它所学习的数据之间的相关性,因此可能不足以揭示因果关系。然而,因果关系涉及到相关性,所以一个可解释的ML模型可以验证因果推理技术提供的结果,或者在现有数据中提供可能的因果关系的第一直觉。同样,表1显示,如果我们关注那些将因果关系明确表述为目标的论文数量,因果关系就不是最重要的目标之一。
-
可转移性Transferability: 模型总是受到一些约束,这些约束应该考虑到模型的无缝可转移性。这就是为什么在处理ML问题时使用训练-测试方法的主要原因[162,163]。可解释性也是可转移性的倡导者,因为它可以简化阐明可能影响模型的边界的任务,从而更好地理解和实现。类似地,仅仅理解模型中发生的内部关系有助于用户在另一个问题中重用这些知识。在某些情况下,缺乏对模型的正确理解可能会将用户推向错误的假设和致命的后果[44,164]。可转移性也应该落在可解释模型的结果属性之间,但同样,不是每个可转让性模型都应该被认为是可解释的。正如在表1中所观察到的,大量的论文指出,将一个模型描述为可解释的是为了更好地理解复用它或提高它的性能所需要的概念,这是追求模型可解释性的第二个最常用的理由。
-
信息性Informativeness: ML模型的最终目的是支持决策[92]。然而,不应该忘记的是,模型所解决的问题并不等于它的人类对手所面临的问题。因此,为了能够将用户的决策与模型给出的解决方案联系起来,并避免陷入误解的陷阱,需要大量的信息。为此,可解释的ML模型应该提供有关正在处理的问题的信息。在文献综述中发现的主要原因是为了提取模型内部关系的信息。几乎所有的规则提取技术都证实了它们在寻找模型内部功能的更简单理解方面的方法,说明知识(信息)可以用这些更简单的代理来表示,它们认为这些代理可以解释先行词。这是在综述的论文中发现的最常用的论点,用来支持他们所期望的可解释模型。
-
置信度Confidence: 作为稳健性和稳定性的概括,置信度的评估应该始终基于一个预期可靠性的模型。在控制下保持信心的方法因模型的不同而不同。正如在[165,166,167]中所述,当从某个模型中提取解释时,稳定性是必须具备的。可靠的解释不应该由不稳定的模型产生。因此,一个可解释的模型应该包含关于其工作机制可信度的信息。
-
公平性Fairness:从社会的角度来看,在ML模型中,可解释性可以被认为是达到和保证公平性的能力。在一个特定的文献链中,一个可解释的ML模型建议对影响结果的关系进行清晰的可视化,允许对手头的模型进行公平或伦理分析[3,100]。同样,XAI的一个相关目标是强调模型所暴露的数据中的偏差[168,169]。在涉及人类生活的领域,对算法和模型的支持正在迅速增长,因此,可解释性应被视为避免不公平或不道德地使用算法输出的桥梁。
-
Accessibility可访问性: 评审贡献的认为可解释性是允许最终用户更多地参与改进和开发某个ML模型的过程的属性[37,86]。显然,可解释的模型将减轻非技术或非专业用户在处理乍一看似乎不可理解的算法时的负担。这一概念在被调查的文献中被认为是第三个最重要的目标。
-
交互性Interactivity: 一些贡献[50,59]包括模型与用户交互的能力,这是可解释的ML模型的目标之一。同样,这个目标与最终用户非常重要的领域相关,他们调整模型并与之交互的能力是确保成功的关键。
-
隐私意识Privacy awareness: 在回顾的文献中,几乎被遗忘的是,ML模型中可解释性的副产品之一是它评估隐私的能力。ML模型可能具有其所学习模式的复杂表示。无法理解模型[4]捕获并存储在其内部表示中的内容可能会导致隐私被破坏。相反,由未经授权的第三方解释训练过的模型的内部关系的能力也可能会损害数据来源的差异隐私。由于其在XAI预计将发挥关键作用的行业中的重要性,机密性和隐私问题将分别在第5.4和6.3小节中进一步讨论。
本小节回顾了所调研论文的广泛范围内所涉及的目标。所有这些目标都清楚地隐藏在本节前面介绍的可解释性概念的表面之下。为了总结之前对可解释性概念的分析,最后一小节讨论了社区为解决ML模型中的可解释性所采取的不同策略。
2.5 怎么样?
文献明确区分了可以通过设计解释的模型和可以通过外部XAI技术解释的模型。这种双重性也可以看作是可解释模型与模型可解释技术的区别;更广泛接受的分类是透明模型和事后可解释性。同样的对偶性也出现在[17]的论文中,作者所做的区分是指解决透明盒设计问题的方法,而不是解释黑盒子问题的方法。这项工作进一步扩展了透明模型之间的区别,包括考虑的不同透明度级别。
在透明性中,考虑了三个层次: 算法透明性、可分解性和可模拟性。在后设技术中,我们可以区分文本解释、可视化、局部解释、实例解释、简化解释和特征关联。在这种情况下,[24] 提出了一个更广泛的区别: 1)区分不透明的系统,其中从输入到输出的映射对用户来说是不可见的; 2)可解释系统,用户可以对映射进行数学分析; 3)可理解的系统,在这个系统中,模型应该输出符号或规则以及它们的特定输出,以帮助理解映射背后的基本原理。最后一个分类标准可以被认为包含在前面提出的分类标准中,因此本文将尝试遵循更具体的分类标准。
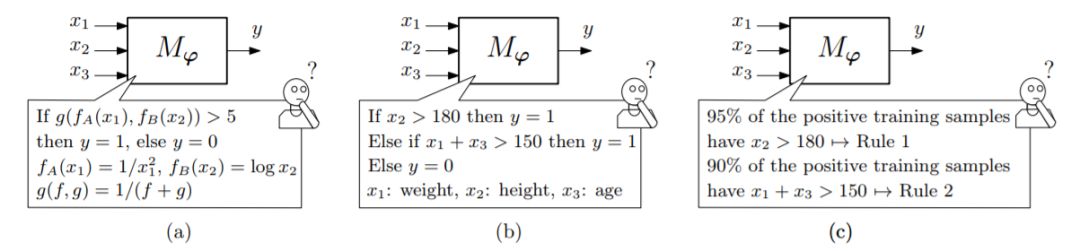
图4. 概念图举例透明度的不同层次描述Mϕ毫升模型,与ϕ表示模型的参数集的手:(一)可模拟性;(b)可分解性;(c)算法的透明度。
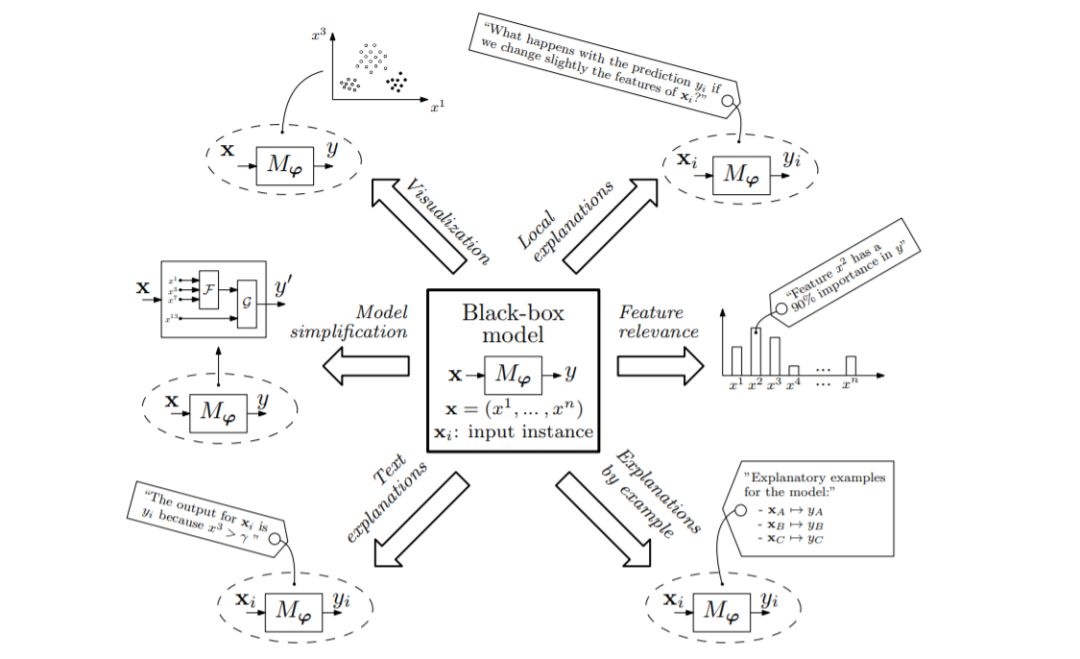
图5. 概念图显示了不同的因果explainability方法可供Mϕ毫升模型
3. 透明机器学习模型
前一节介绍了透明模型的概念。如果一个模型本身是可以理解的,那么它就被认为是透明的。本节调查的模型是一套透明模型,它可以属于前面描述的模型透明性的一个或所有级别(即可模拟性、可分解性和算法透明性)。在接下来的部分中,我们提供了该语句的理由,并提供了图6与图7中所示支持。
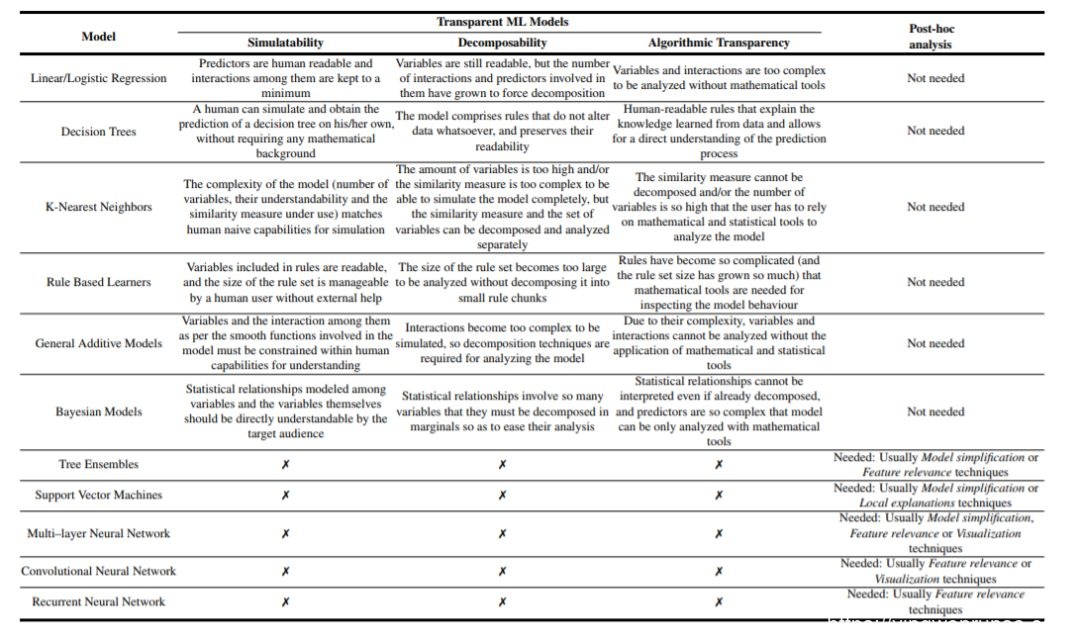
图6:ML模型可解释性分类的总体情况
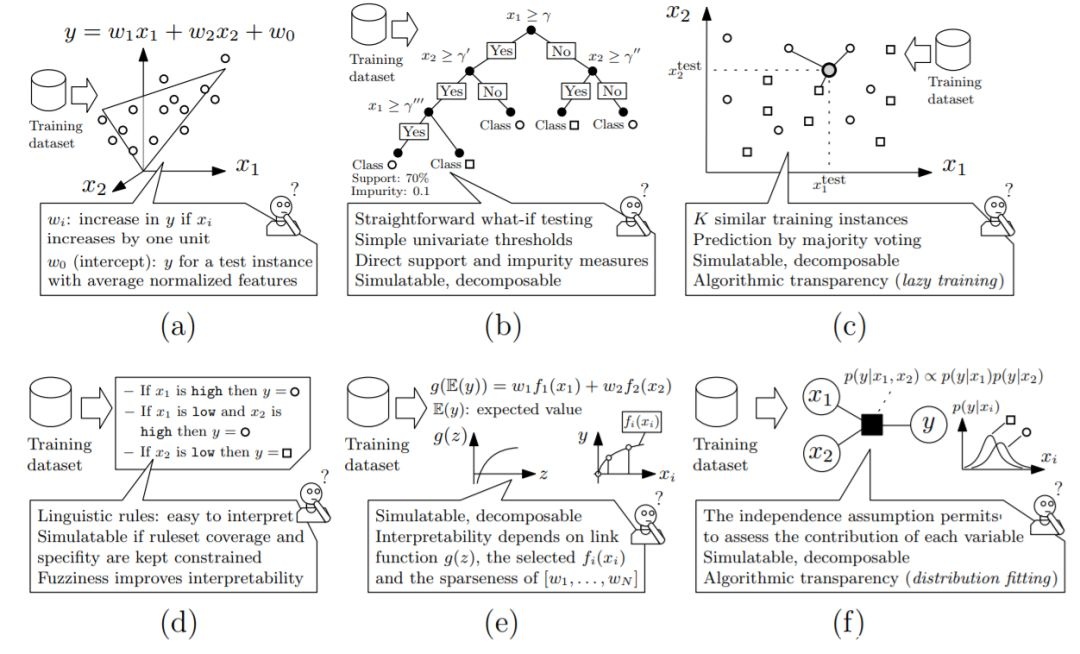
图7: 本综述中所考虑的不同ML模型的透明度水平的图形说明:(a)线性回归;(b)决策树;(c)再邻居;(d)基于规则的学习者;(e)广义可加模型;(f)贝叶斯模型。
4. 机器学习模型的后解释技术:分类法、浅层模型和深度学习
当ML模型不满足宣布它们透明的任何标准时,必须设计一个单独的方法并应用于模型来解释它的决策。这就是事后可解释性技术(也称为建模后可解释性)的目的,它的目的是交流关于已经开发的模型如何对任何给定输入产生预测的可理解信息。在本节中,我们将对不同的算法方法进行分类和回顾,这些算法方法用于事后可解释性,区别于1) 那些为应用于任何类型的ML模型而设计的算法方法; 2) 那些是为特定的ML模型设计的,因此,不能直接推断到任何其他学习者。现在,我们详细阐述了不同ML模型的事后可解释性方面的趋势,这些趋势在图8中以分层目录的形式进行了说明,并在下面进行了总结:
-
用于事后解释的模型无关技术(4.1小节),可以无缝地应用于任何ML模型,而不考虑其内部处理或内部表示。
-
专为解释某些ML模型而定制或专门设计的事后解释能力。我们将我们的文献分析分为两个主要的分支:浅层ML模型的事后可解释性的贡献,这些贡献统称为所有不依赖于神经处理单元的分层结构的ML模型(第4.2小节);以及为深度学习模型设计的技术,这些技术相应地表示神经网络家族和相关变体,如卷积神经网络、递归神经网络(4.3小节)和包含深度神经网络和透明模型的混合方案。对于每一个模型,我们都对研究界提出的最新的事后方法进行了彻底的审查,并确定了这些贡献所遵循的趋势。
-
我们以4.4小节结束了我们的文献分析,在4.4小节中,我们提出了第二种分类法,通过对处理深度学习模型的事后解释的贡献进行分类,对图6中更一般的分类进行了补充。为此,我们将重点关注与这类黑盒ML方法相关的特定方面,并展示它们如何链接到第一种分类法中使用的分类标准。
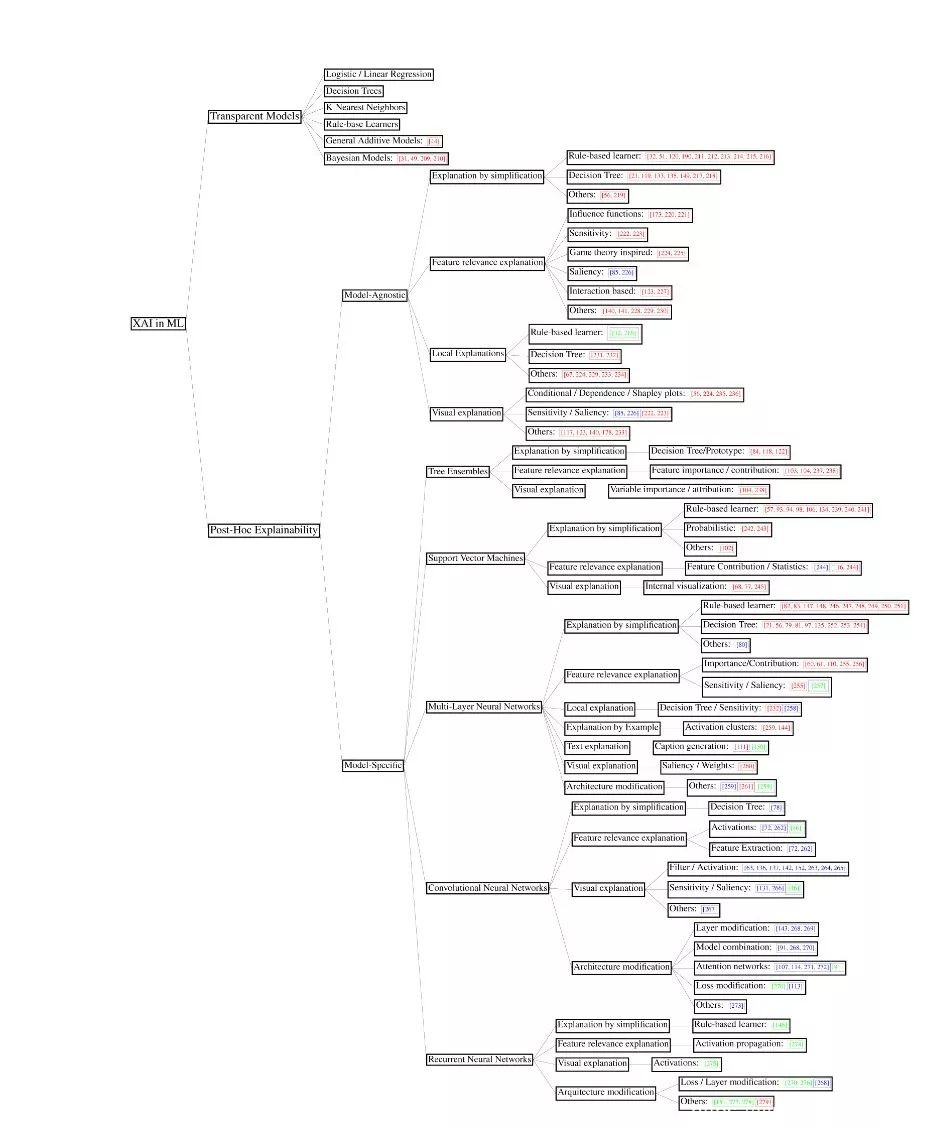
图8. 综述文献的分类和与不同ML模型相关的可解释性技术的趋势。用蓝色、绿色和红色框起来的引用分别对应于使用图像、文本或表格数据的XAI技术。为了建立这种分类法,对文献进行了深入分析,以区分是否可以将后适应技术无缝地应用于任何ML模型,即使在其标题和/或摘要中明确提到了深度学习。
4.1 用于事后可解释性的模型不可知技术
用于事后可解释性的模型无关技术被设计成插入到任何模型,目的是从其预测过程中提取一些信息。有时,使用简化技术来生成模仿其前身的代理,目的是为了获得易于处理和降低复杂性的东西。其他时候,意图集中在直接从模型中提取知识,或者简单地将它们可视化,以简化对其行为的解释。根据第2节中介绍的分类法,与模型无关的技术可能依赖于模型简化、特征相关性估计和可视化技术。
4.2 浅ML模型的事后解释能力
Shallow ML覆盖了多种监督学习模型。在这些模型中,有一些严格可解释的(透明的)方法(如KNN和决策树,已经在第3节中讨论过)。考虑到它们在预测任务中的突出地位和显著性能,本节将集中讨论两种流行的浅ML模型(树集成和支持向量机,SVMs),它们需要采用事后可解释性技术来解释它们的决策
4.3 深度学习的可解释性
事后局部解释和特征相关技术正日益成为解释DNNs的主要方法。本节回顾了最常用的DL模型,即多层神经网络、卷积神经网络(CNN)和递归神经网络(RNN)的可解释性研究。
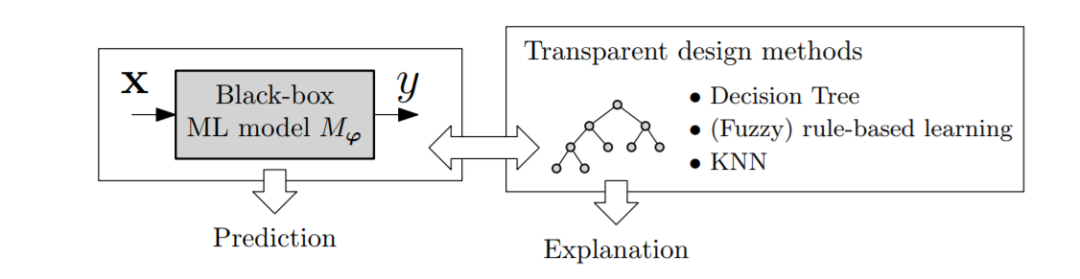
图9: 混合模型的图示。一个被认为是黑箱的神经网络可以通过将其与一个更具解释性的模型相关联来解释,如决策树[298]、一个(模糊的)基于规则的系统[19]或KNN[259]。
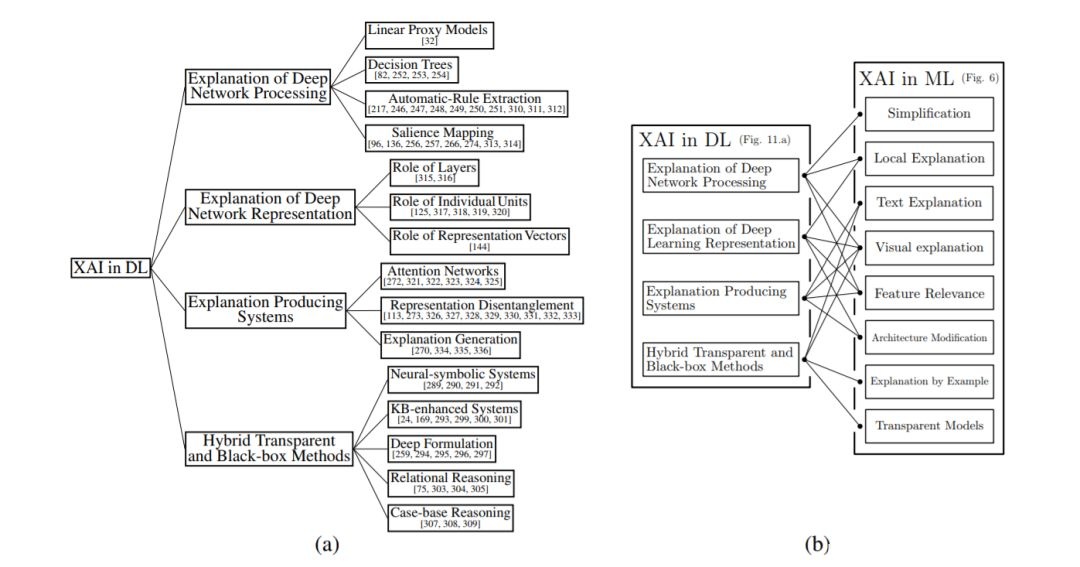
图10:(a) 可选的深度学习特定分类扩展自[13]的分类;(b)它与图6中的分类法的联系。
5. XAI:机遇、挑战和研究需求
现在,我们利用已完成的文献回顾,对ML和数据融合模型的可解释性领域的成就、趋势和挑战提出了批评。实际上,我们在讨论到目前为止在这一领域取得的进展时,已经预见到了其中的一些挑战。在本节中,我们将重新审视这些问题,并为XAI探索新的研究机会,找出可能的研究路径,以便在未来几年有效地解决这些问题:
在可解释性和性能之间的权衡
可解释性与性能的问题是一个随着时间不断重复的问题,但就像任何其他大命题一样,它的周围充满了神话和误解。
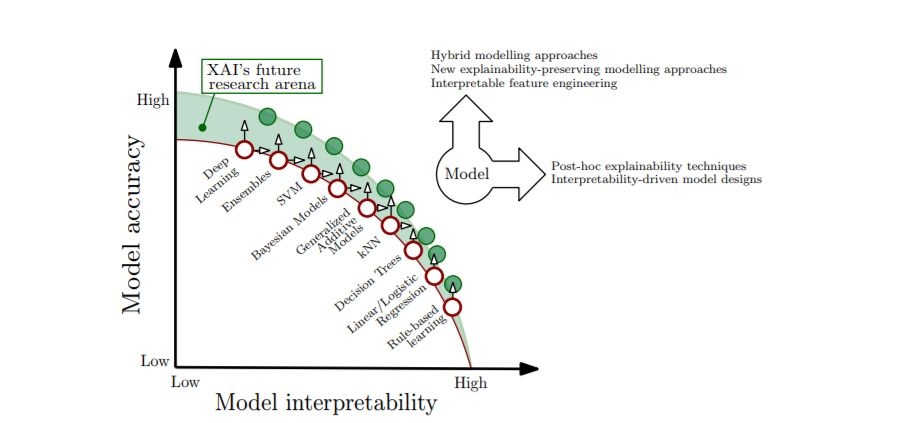
图11: 模型可解释性和性能之间的权衡,以及XAI技术和工具潜力所在的改进领域的表示
6. 走向负责任的人工智能:人工智能、公平、隐私和数据融合的原则
多年来,许多组织,无论是私人的还是公共的,都发布了指导方针,指出人工智能应该如何开发和使用。这些指导方针通常被称为人工智能原则,它们处理与个人和整个社会潜在的人工智能威胁相关的问题。本节将介绍一些最重要和被广泛认可的原则,以便将XAI(通常出现在它自己的原则中)与所有这些原则联系起来。如果在实践中寻求一个负责任的AI模型的实现和使用,我们公司声称XAI本身是不够的。其他重要的人工智能原则,如隐私和公平,在实践中必须谨慎处理。在接下来的章节中,我们将详细阐述负责任人工智能的概念,以及XAI和数据融合在实现其假设原则中的含义。
6.1 人工智能原则 Principles of Artificial Intelligence
-
使用人工智能系统后的输出不应导致在种族、宗教、性别、性取向、残疾、种族、出身或任何其他个人条件方面对个人或集体产生任何形式的歧视。因此,在优化人工智能系统的结果时要考虑的一个基本标准不仅是它们在错误优化方面的输出,而且是系统如何处理这些状况。这定义了公平AI的原则。
-
人们应该知道什么时候与人交流,什么时候与人工智能系统交流。人们还应该知道他们的个人信息是否被人工智能系统使用,以及用于什么目的。确保对人工智能系统的决策有一定程度的理解是至关重要的。这可以通过使用XAI技术来实现。重要的是,生成的解释要考虑将接收这些解释的用户的配置文件(根据小节2.2中给出的定义,所谓的受众),以便调整透明度级别,如[45]中所示。这定义了透明和可解释AI的原则。
-
人工智能产品和服务应始终与联合国的可持续发展目标保持一致[375],并以积极和切实的方式为之做出贡献。因此,人工智能应该总是为人类和公共利益带来好处。这定义了以人为中心的人工智能的原则(也称为社会公益的人工智能[376])。
-
人工智能系统,尤其是当它们由数据提供信息时,应该在其整个生命周期中始终考虑隐私和安全标准。这一原则并不排斥人工智能系统,因为它与许多其他软件产品共享。因此,它可以从公司内部已经存在的流程中继承。这通过设计定义了隐私和安全的原则,这也被认为是负责任的研究和创新范式下智能信息系统面临的核心伦理和社会挑战之一(RRI,[377])。RRI指的是一套方法学指南和建议,旨在从实验室的角度考虑更广泛的科学研究背景,以应对全球社会挑战,如可持续性、公众参与、伦理、科学教育、性别平等、开放获取和治理。有趣的是,RRI还要求在遵循其原则的项目中确保开放性和透明度,这与前面提到的透明和可解释的AI原则直接相关。
-
作者强调,所有这些原则都应该扩展到任何第三方(供应商、顾问、合作伙伴……)
6.2 公平和责任
如前一节所述,除了XAI之外,在过去十年中发布的不同AI原则指导方针中还包括许多关键方面。然而,这些方面并不是完全脱离了XAI;事实上,它们是交织在一起的。本节介绍了与人工智能原则指导具有巨大相关性的两个关键组成部分,即公平性和可说明性。这也突出了它们与XAI的联系。
6.3 隐私与数据融合
如今,几乎所有领域的活动中都存在着越来越多的信息源,这就要求采用数据融合方法,同时利用这些信息源来解决学习任务。通过合并异构信息,数据融合已被证明可以在许多应用程序中提高ML模型的性能。本节通过数据融合技术的潜力进行推测,以丰富ML模型的可解释性,并对从中学习ML模型的数据的私密性做出妥协。为此,我们简要概述了不同的数据融合范式,并从数据隐私的角度进行了分析。我们稍后会讲到,尽管XAI与负责任的人工智能相关,但在当前的研究主流中,XAI与数据融合是一个未知的研究领域。
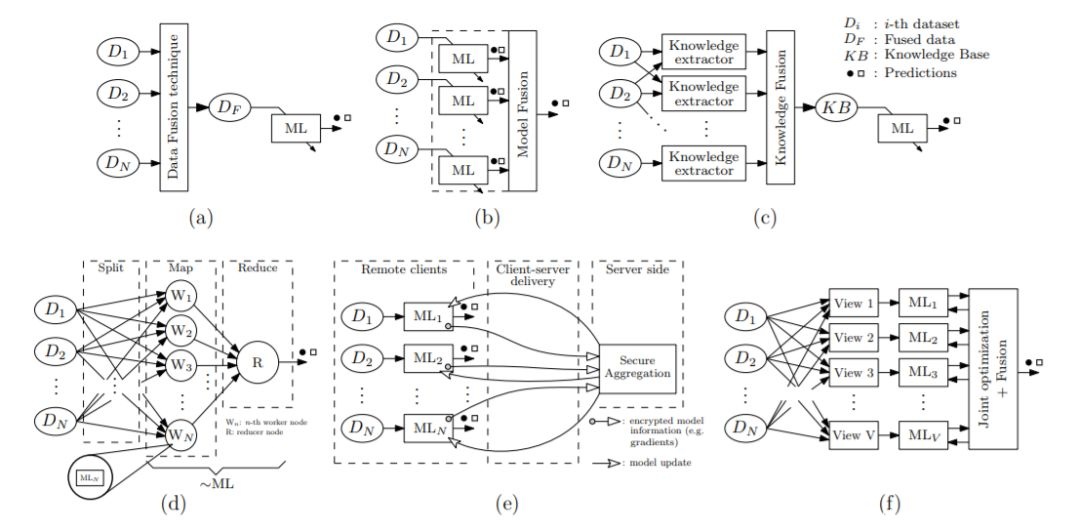
图12: 显示可以执行数据融合的不同级别的关系图:(a)数据级别;(b)模型;(c)知识水平;(d)大数据融合;(e)联邦学习和(f)多视图学习。
7. 结论和展望
这篇综述围绕着可解释的人工智能(XAI)展开,它最近被认为是在现实应用中采用ML方法的最大需求。我们的研究首先阐明了模型可解释性背后的不同概念,并展示了激发人们寻找更多可解释的ML方法的各种目的。这些概念性的评注已经成为一个坚实的基础,系统地回顾最近关于可解释性的文献,这些文献从两个不同的角度进行了探讨:1) ML模型具有一定程度的透明性,因此可以在一定程度上自行解释; 2) 后特设XAI技术的设计,使ML模型更容易解释。这个文献分析已经产生了一个由社区报告的不同提案的全球分类,在统一的标准下对它们进行分类。在深入研究深度学习模型可解释性的贡献越来越普遍的情况下,我们深入研究了有关这类模型的文献,提出了一种可选择的分类方法,可以更紧密地连接深度学习模型可解释性的具体领域。
我们的讨论已经超越了XAI领域目前所取得的成果,转向了负责任的AI概念,即在实践中实现AI模型时必须遵循的一系列AI原则,包括公平、透明和隐私。我们还讨论了在数据融合的背景下采用XAI技术的含义,揭示了XAI在融合过程中可能会损害受保护数据的隐私。对XAI在公平方面的含义也进行了详细的讨论。
我们对XAI未来的思考,通过在整个论文中进行的讨论,一致认为有必要对XAI技术的潜力和警告进行适当的理解。我们的设想是,模型的可解释性必须与数据隐私、模型保密性、公平性和可靠性相关的需求和约束一起解决。只有联合研究所有这些人工智能原则,才能保证在全世界的组织和机构中负责任地实施和使用人工智能方法。
参考文献
-
S. J. Russell, P. Norvig, Artificial intelligence: a modern approach, Malaysia; Pearson Education Limited,, 2016.
-
D. M. West, The future of work: robots, AI, and automation, Brookings Institution Press, 2018.
-
S. J. Russell, P. Norvig, Artificial intelligence: a modern approach,Malaysia; Pearson Education Limited,, 2016.
-
D. M. West,The future of work: robots, AI, and automation, Brookings Institution Press,2018.
-
B. Goodman,S. Flaxman, European union regulations on algorithmic decision-making and aright
-
to explanation, AI Magazine 38 (3) (2017) 50–57.
-
D. Castelvecchi, Can we open the black box of AI?, Nature News 538(7623) (2016) 20.
-
Z. C. Lipton, The mythos of model interpretability, Queue 16 (3)(2018) 30:31–30:57.
-
A. Preece, D. Harborne, D. Braines, R. Tomsett, S. Chakraborty,Stakeholders in Explainable AI (2018). arXiv:1810.00184.
-
D. Gunning, Explainable artificial intelligence (xAI), Tech. rep.,Defense Advanced Research Projects Agency (DARPA) (2017).
-
E. Tjoa, C. Guan, A survey on explainable artificial intelligence(XAI): Towards medical XAI (2019). arXiv:1907.07374.
-
J. Zhu, A. Liapis, S. Risi, R. Bidarra, G. M. Youngblood, ExplainableAI for designers: A humancentered perspective on mixed-initiative co-creation,2018 IEEE Conference on Computational
-
Intelligence and Games (CIG) (2018) 1–8.
-
F. K. Do˜silovi´c, M. Br˜ci´c, N. Hlupi´c, Explainable artificialintelligence: A survey, in: 41st International Convention onInformation and Communication Technology, Electronics and Microelectronics (MIPRO),2018, pp. 210–215.
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“可解释AI” 就可以获取《可解释人工智能(XAI): 概念体系机遇和挑战—构建负责任的人工智能Explainable Artificial Intelligence (XAI)》论文专知下载链接索引~





评论前必须登录!
立即登录 注册