Iris(鸢尾花)无疑是实战机器学习的第一课中的最最最著名的数据集,而这款工具也因此得名,一整月的数据提取工作只需几分钟即可完成,准确率高达 90%!
它实际上Iris.ai 适用于所有Research处理的综合平台:智能搜索和各种智能过滤器、阅读列表分析、自动生成摘要、自主提取和系统化数据。
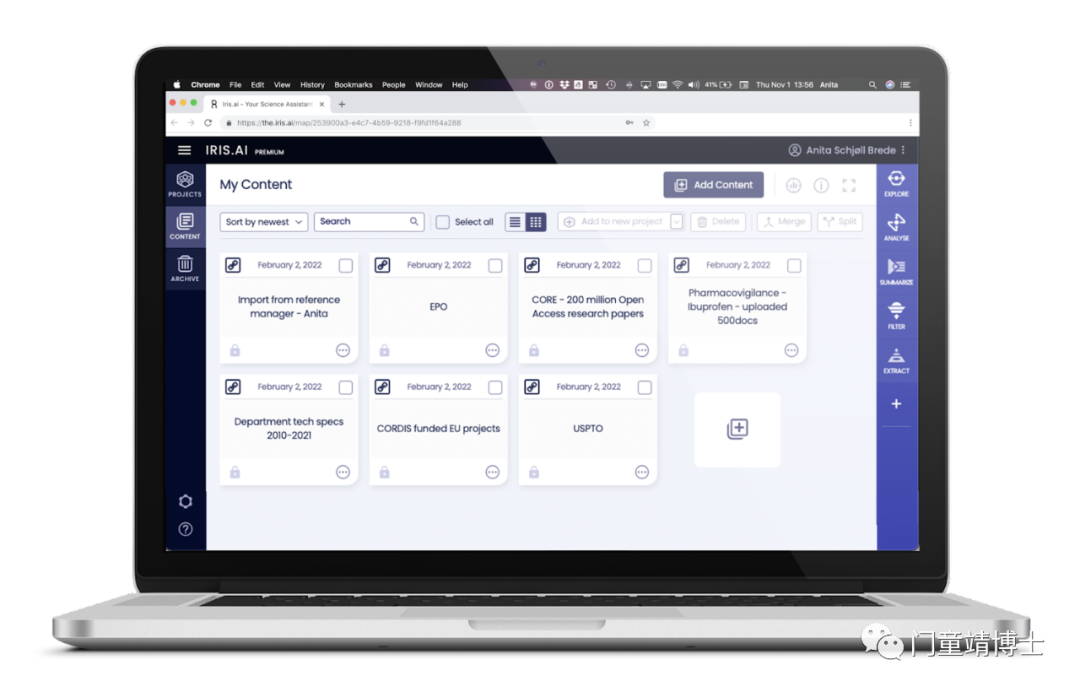
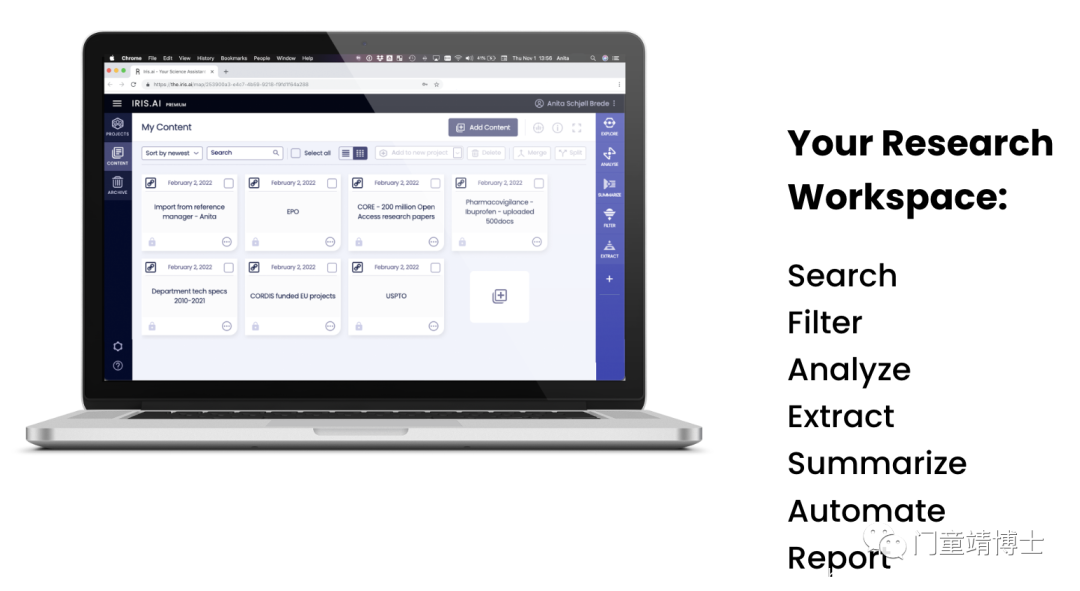
它推出的Research workspace,以内容为中心,它包括这些模块:搜索、过滤、分析、提取、总结、自动化、报告。
主要特点是该系统的模型无需再训练,可以自定义工作流程,以及支持各种类型的文档。
Iris. AI 的主要十大特性~
1. Research Workspace
它是一个功能强大的软件套件,研究内容位于其中。你可以上传任何研究文档集合,或直接连接到实时代理数据集,例如出版商、专利机构、内部存储库或与您的研究相关的任何其他来源。
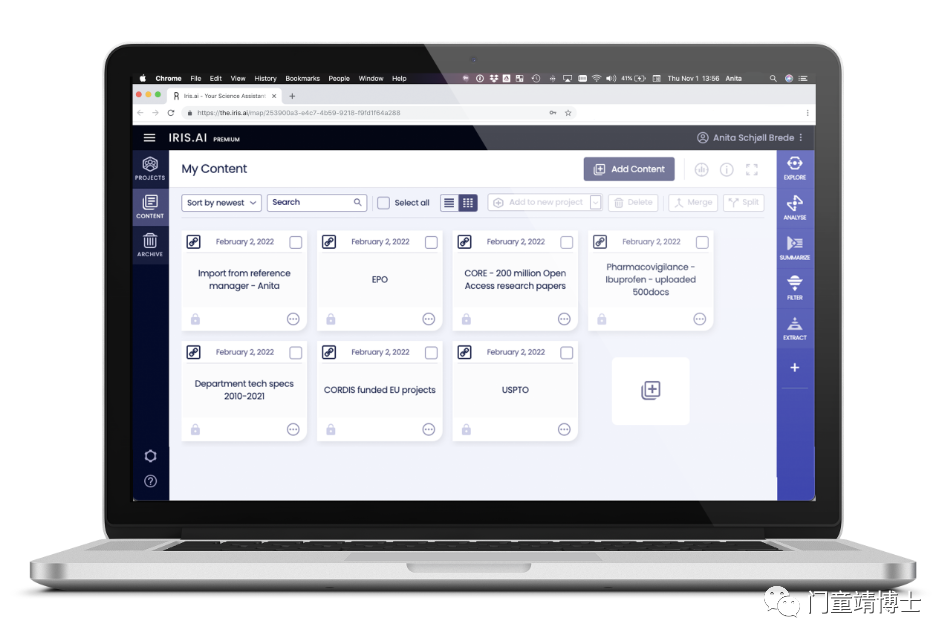
添加内容后,你可以使用各种智能工具,您可以根据需要应用和组合这些工具。每个研究过程都略有不同,您的研究工作区将支持任何工作流程。
2. 强化你的研究领域
Iris.ai 机器学习引擎经过大量科学文章的训练。领域适应对于通过加强特定领域内各个单词(“标记”)的含义来提高更狭窄领域中的结果质量非常重要。这种情况在很少或没有人际互动的情况下就会发生。 你所需要做的就是向 Iris.ai 系统提供 10-20 份与您的研究领域相关的代表性文件。这可以是较大领域的广泛表示或狭窄的子域。该机器将开放获取文献扩大到包含约 2000 个文档的数据集,然后构建特定于您所在领域的新词汇表,并在这个新词汇量的基础上强化自身。
你所需要做的就是向 Iris.ai 系统提供 10-20 份与您的研究领域相关的代表性文件。这可以是较大领域的广泛表示或狭窄的子域。该机器将开放获取文献扩大到包含约 2000 个文档的数据集,然后构建特定于您所在领域的新词汇表,并在这个新词汇量的基础上强化自身。
3. 支持多来源和本地内容
在研究人员工作区中,你可以处理多数任何类型的科学研究内容,无论是开放获取还是付费研究论文、专利、内部文档、灰皮书、白皮书、技术规格,凡是您能想到的内容。跨多种来源进行联合搜索可以节省大量时间。 Iris.ai 研究人员工作区附带各种数据集,您可以直接加载到您自己的工作区中。这包括来自 Core.ac.uk 的全球大部分开放获取内容,以及 PubMed、美国专利局和 CORDIS(所有欧盟资助的研究项目)。您可以选择集成更多这些代理数据集(内容的实时集合),例如来自付费订阅内容或您自己存储的内部或外部研究文档。然后,这些代理数据集将在您的工作区中定期更新,并且您可以选择接收符合每个项目处理标准的新文档的提醒。
Iris.ai 研究人员工作区附带各种数据集,您可以直接加载到您自己的工作区中。这包括来自 Core.ac.uk 的全球大部分开放获取内容,以及 PubMed、美国专利局和 CORDIS(所有欧盟资助的研究项目)。您可以选择集成更多这些代理数据集(内容的实时集合),例如来自付费订阅内容或您自己存储的内部或外部研究文档。然后,这些代理数据集将在您的工作区中定期更新,并且您可以选择接收符合每个项目处理标准的新文档的提醒。
每个用户还可以简单地选择上传文档列表,通过直接从他们的计算机上传、通过他们的个人云存储,或通过例如从参考文献管理器导出的 BibTex 文件。这些数据集是静态的,可以像连接的内容数据库一样在工具中进一步处理。
4. 支持按全文描述搜索
在新的研究项目开始时,您并不总是知道自己在寻找什么。关键词成为限制因素,尤其是在您不熟悉每个感兴趣领域的词汇的跨学科研究挑战中。 Iris.ai Explore 搜索是一种所谓的基于内容的推荐引擎。你的起点是给机器一个文本——要么是你自己写的对你试图解决的问题的描述,要么是另一篇研究论文或文档。该工具将识别文本中最有意义的单词,用上下文同义词和上位词丰富文本,并将所有这些转化为“指纹”,该指纹将与每篇论文的指纹相匹配,与你选择的所有来源进行关联。
Iris.ai Explore 搜索是一种所谓的基于内容的推荐引擎。你的起点是给机器一个文本——要么是你自己写的对你试图解决的问题的描述,要么是另一篇研究论文或文档。该工具将识别文本中最有意义的单词,用上下文同义词和上位词丰富文本,并将所有这些转化为“指纹”,该指纹将与每篇论文的指纹相匹配,与你选择的所有来源进行关联。
5. 上下文过滤
一些包含/排除标准很简单:它们可以很容易地用一个或三个关键字来表达。不幸的是,情况并非总是如此——更常见的是,标准可以更容易地在上下文描述中表达。例如,化学品的应用背景或药物的预期用途。

使用工作区的上下文过滤器,您可以编写自己的约 50-100 个单词的上下文描述,该描述与内容列表中的每篇文章相匹配。你可以根据需要添加任意数量,并使用它们来包含或排除。想象一下应用于您的阅读列表的上下文维恩图,让你可以快速筛选。
6. 数据过滤
对于某些过滤任务,需要详细的特异性。无论你需要过滤实体、特定数据点还是数据范围,高级过滤都会从文档中提取并识别准确的信息,然后您可以使用文章中识别的变量来过滤列表。

需要知道,在你面前的500份文件中,哪一份报告了抗拉强度在600-650兆帕之间的钢材?或者 PubMed 中是否有论文报道布洛芬的恶心不良反应发生率超过 5%?这就是高级过滤的用途。
7. 数据提取(Data Extraction)
从包含自由文本、表格、图表、图形和大量布局的 PDF 中手动提取并链接所需的数据需要高技能的体力劳动。Iris.ai 的 Extract 工具提取这些文档中的所有关键数据并将其链接为表格、机器可读的系统格式。一整月的数据提取工作只需几分钟即可完成,准确率高达 90%。
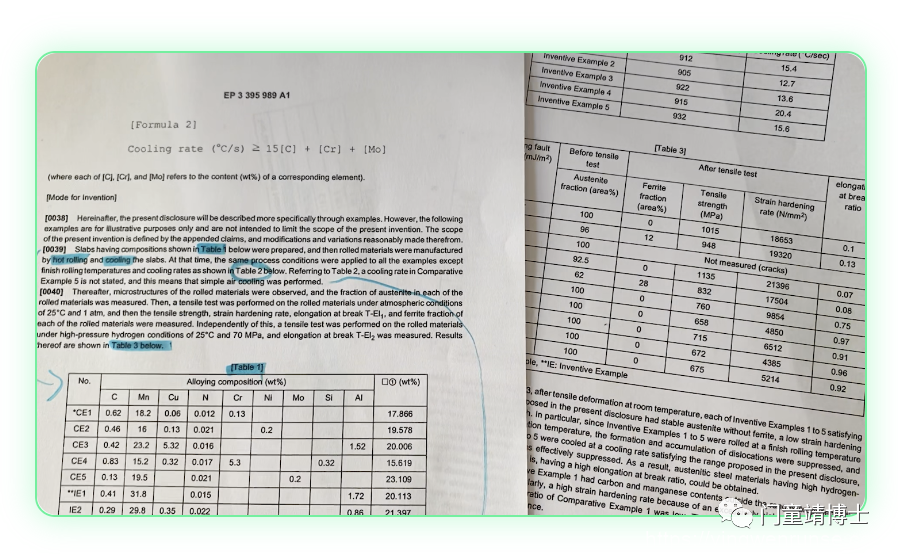
包含要提取的相关数据点的 PDF 被发送到 Iris.ai 系统。该 PDF 可以是专利、临床试验报告、研究论文或任何其他相关类型的科学或技术内容。它可以一次是一个简单的文档,也可以是一批中数百或数千个文档。
Iris.ai 引擎提取文本并识别所有特定于域的实体,然后定位表格并从行和列中提取数据,并链接文本和表格之间的数据。然后引擎以机器可读的格式填充预定义的输出;Excel 工作表、集成实验室工具、数据库或你需要的任何其他内容。
8. 机器生成的摘要(Abstract)
Iris.ai 工作区配备了可配置的摘要引擎。它可以快速生成多个摘要、一篇全文或多篇全文文档的摘要。这些摘要非常适合快速审查类似文档的较大文档集,或者启动你的学术写作。
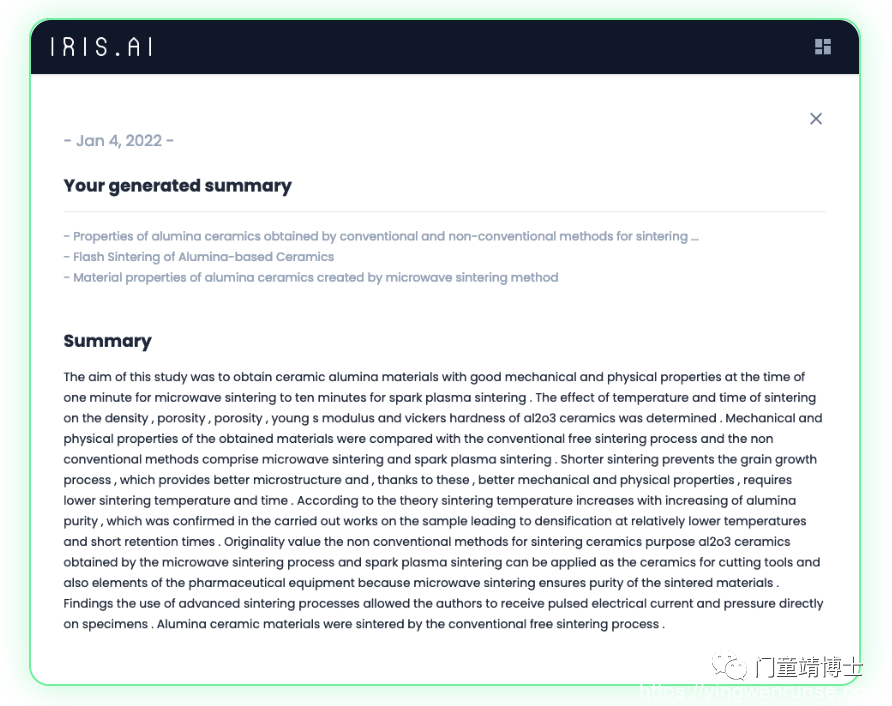
Iris.ai 摘要工具进行抽象摘要,这意味着该工具实际上编写自己的摘要,而不是将句子复制粘贴在一起(称为提取摘要)。你也可以配置摘要 – 是你需要的 10 个文档的简短两句话摘要,还是 20 页文档的一页摘要?
9. 文档集分析
当你遇到一组搜索结果时(在将内容导入 Iris.ai 之前通过探索工具或其他搜索工具进行搜索),您可能很难知道要过滤哪些内容(包括或排除)。处理未知的未知因素可能需要大量的尝试和错误以及阅读标题。通过工作区的文档集分析,你将快速了解文档集的内容。
分析文档集后(支持从少量文档到最多 20,000 个文档),您将看到各种结果:
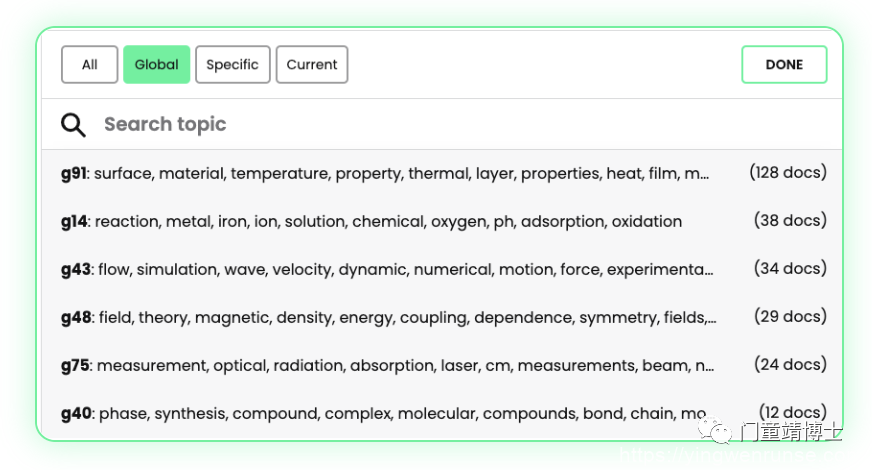
您将看到文献列表的主题组,包括全局主题(从整体科学水平来看这些文章属于哪些主题)以及特定主题(在此阅读列表中,文章属于哪些主题) 。由于一篇文章可以属于多个主题组,因此这是一种选择要包含和排除的组而不会错过任何相关文档的有用方法。
您还可以探索文档集中最有意义的单词、在上下文中可能具有特殊含义的罕见单词以及它们的所有相关同义词。
10. 实时监控更新
当初始文档集来自一个或多个代理数据集(即“实时”来源)时(例如内部存储库、PubMed、USPTO),你所做的每项搜索、过滤、分析甚至提取都可以设置为监控代理,从而获取符合您确切标准的新文档。

这远远超出了在搜索引擎中订阅主题或关键字的范围。在这里,你可以自动执行整个过程,定期运行,并收到通知,例如,当从完全符合您的纳入排除标准的新文章中提取临床数据并提供给您时,您会收到通知。
为什么选择 IRIS.AI?
在过去的 5 年里,IRIS.AI一直致力于构建一个屡获殊荣的人工智能引擎,用于科学文本理解。我们的文本相似性、表格数据提取、特定领域实体表示学习以及实体消歧和链接算法达到了世界最佳水平。最重要的是,IRIS.AI的机器构建了一个包含所有实体及其链接的综合知识图,以允许人类从中学习、使用它并向系统提供反馈。
那么我们尝试一下IRIS.AI的实际效果如何~
我们Request a demo;
大约在5秒之内,你会收到Iris的邮件;
邮件中回复需要1~2个工作日来获取Demo。
以上,实际的使用体验或许只有等到Demo到手之后,才能体会到这套体系化的AI工具。
总体上看这是一套体系化的可以用于科研AI平台工具,从特性描述上来看, 个性化加强的研究领域、相关文献的检索、智能化的Data Extraction和批量化文档分析的功能最为值得期待。
后续Demo尝试过后,再与大家分享~
参考文献:
[1]https://iris.ai/
[2]https://iris.ai/author/ada/
[3]https://iris.ai/publications/
HAVE FUN!

Let’s SciChat,你的专属AI学术和工程助手
来扫我吧~






评论前必须登录!
立即登录 注册